Privacy Considerations for Chatbots and AI platforms under GDPR
This article deconstructs the seven core principles of the GDPR and provides a critical analysis of their application across the distinct stages of the AI development and deployment lifecycle, highlighting the inherent friction between the regulation's requirements and the operational realities of modern data science.


The General Data Protection Regulation (GDPR) establishes a comprehensive and technologically neutral framework for the protection of personal data. Its core principles, articulated in Article 5, form the bedrock of data protection law within the European Union. However, the advent of sophisticated Artificial Intelligence (AI) systems and conversational platforms, which are inherently data-intensive and often opaque, presents a profound challenge to the application and enforcement of these foundational tenets. This section deconstructs the seven core principles of the GDPR and provides a critical analysis of their application across the distinct stages of the AI development and deployment lifecycle, highlighting the inherent friction between the regulation's requirements and the operational realities of modern data science.
The Seven Pillars of Data Protection (Article 5)
The GDPR is built upon seven fundamental principles that must be adhered to for any processing of personal data. These principles are not merely advisory; they are legally binding requirements that dictate the design, implementation, and governance of any system handling personal information, with non-compliance carrying the risk of substantial financial penalties.
Lawfulness, Fairness, and Transparency
Article 5(1)(a) of the GDPR mandates that personal data shall be "processed lawfully, fairly and in a transparent manner in relation to the data subject". This tripartite principle forms the initial gateway to compliant data processing.
Lawfulness requires that every processing activity must have a valid legal basis as defined in Article 6 of the GDPR. The six potential bases are: consent of the data subject, necessity for the performance of a contract, compliance with a legal obligation, protection of vital interests, performance of a task in the public interest, or legitimate interests pursued by the controller. The choice of legal basis is not arbitrary and must be determined and documented before processing begins.
Fairness is an overarching concept that requires organizations to process personal data in a way that individuals would reasonably expect and not use it in ways that could have unjustified adverse effects on them. It means not purposely withholding information about processing activities or mishandling data in a deceptive manner.
Transparency is intrinsically linked to fairness and is a cornerstone of the GDPR. It obligates data controllers to provide individuals with clear, concise, and easily accessible information about the processing of their personal data. This information, typically conveyed through a privacy notice, must be written in plain language, ensuring that data subjects can understand who is processing their data, why it is being processed, and what their rights are in relation to that processing.
Purpose Limitation
The principle of purpose limitation, found in Article 5(1)(b), dictates that personal data must be "collected for specified, explicit and legitimate purposes and not further processed in a manner that is incompatible with those purposes". This means that an organization must clearly define and document its reasons for collecting personal data at the time of collection. If an organization later wishes to use that data for a new purpose that is deemed incompatible with the original one, it must generally obtain fresh consent from the data subject or have another valid legal basis for the new processing activity. Further processing for archiving purposes in the public interest, or for scientific, historical, or statistical research, is not considered incompatible, provided appropriate safeguards are in place.
Data Minimisation
Under Article 5(1)(c), personal data must be "adequate, relevant and limited to what is necessary in relation to the purposes for which they are processed". This principle of data minimisation requires organizations to collect and retain only the absolute minimum amount of personal data needed to fulfill a specific, defined purpose. For example, a service that only requires an email address to send a newsletter should not also collect a user's phone number or home address. Implementing data minimisation is a key aspect of data protection by design and by default, as it inherently reduces the risk associated with data processing by limiting the potential attack surface and the scope of potential harm in the event of a data breach.
Accuracy
The accuracy principle, outlined in Article 5(1)(d), requires that personal data be "accurate and, where necessary, kept up to date". Data controllers must take every reasonable step to ensure that data which is inaccurate, having regard to the purposes for which it is processed, is erased or rectified without delay. This is an ongoing obligation that necessitates regular data audits and the implementation of processes that allow data subjects to correct their information.
Storage Limitation
Article 5(1)(e) establishes the principle of storage limitation, which states that personal data must be "kept in a form which permits identification of data subjects for no longer than is necessary for the purposes for which the personal data are processed". Organizations must be able to justify the length of time they retain personal data and should establish clear data retention policies. Once the retention period has expired and the data is no longer needed for its original purpose, it should be securely deleted or truly anonymised. Data is only considered truly anonymous if the process is irreversible and the individual is no longer identifiable; pseudonymised data, where re-identification is possible with additional information, is still considered personal data under the GDPR.
Integrity and Confidentiality (Security)
The principle of integrity and confidentiality, found in Article 5(1)(f), is the cornerstone of data security under the GDPR. It mandates that personal data be "processed in a manner that ensures appropriate security of the personal data, including protection against unauthorised or unlawful processing and against accidental loss, destruction or damage, using appropriate technical or organisational measures". This requires a proactive and risk-based approach to security, implementing measures such as encryption, access controls, pseudonymization, and secure data storage to protect data throughout its lifecycle.
Accountability
Finally, the principle of accountability, articulated in Article 5(2), acts as an overarching requirement that binds all other principles together. It states that the "controller shall be responsible for, and be able to demonstrate compliance with" the preceding six principles. This is not a passive obligation; it requires organizations to actively implement appropriate technical and organizational measures and to maintain comprehensive records to prove their compliance. Key accountability measures include maintaining records of processing activities (ROPAs), conducting Data Protection Impact Assessments (DPIAs) for high-risk processing, appointing a Data Protection Officer (DPO) where required, and implementing data protection by design and by default.
The accountability principle effectively transforms the other six principles from abstract legal requirements into operational mandates. It forces an organization to internalize its compliance obligations and create a tangible, auditable trail of its data protection decisions and measures. In the context of complex and often opaque AI systems, where demonstrating fairness or purpose limitation can be exceptionally challenging, the documentation and governance frameworks mandated by the accountability principle become the primary mechanism through which regulators can assess compliance. A failure in documentation is not merely a procedural lapse; it is a substantive failure to comply with a core tenet of the GDPR. This means that for AI development, robust governance and meticulous record-keeping are not just best practices but a direct and enforceable requirement of the regulation.
Application to the AI Lifecycle
The linear, principle-based framework of the GDPR encounters significant friction when applied to the cyclical and data-hungry lifecycle of AI development. Each stage—from initial data sourcing to ongoing model monitoring—presents unique challenges to the core tenets of data protection. A compliant approach requires a systematic application of the principles at every step, transforming them from legal abstractions into concrete engineering and governance requirements.
Data Sourcing and Pre-processing
This initial stage, where vast quantities of data are collected and prepared for training, is arguably the most contentious from a GDPR perspective.
Lawfulness, Fairness, and Transparency: Establishing a valid legal basis for sourcing massive datasets is a primary hurdle. For data scraped from the public internet, obtaining explicit consent is often impractical or impossible. Consequently, organizations frequently turn to "legitimate interests" (Article 6(1)(f)) as the legal basis. However, this is not a carte blanche; it requires a rigorous, documented Legitimate Interest Assessment (LIA) that balances the controller's interests against the rights and freedoms of the data subjects. European data protection authorities have indicated that this balancing test is stringent, particularly when processing is complex and not within the reasonable expectations of individuals. Furthermore, any data processing that infringes upon other laws, such as copyright through web scraping, is inherently unlawful under the GDPR.
Purpose Limitation and Data Minimisation: The very concept of training large, general-purpose foundational models often conflicts with these principles. The data is collected not for a single, specified purpose, but for a broad range of potential future applications, many of which are unknown at the time of collection. This "collect now, figure out uses later" approach is antithetical to the GDPR's framework. Recognizing this tension, some regulators, like France's CNIL, have suggested a more flexible interpretation for general-purpose AI, where the purpose can be described by the
type of system being developed and its key potential functionalities, rather than an exhaustive list of all possible uses. Nonetheless, the obligation to minimize data remains; datasets should be curated, selected, and cleaned to remove personal data that is not essential for training.
Model Training and Validation
During this stage, the prepared data is used to train and test the AI model's performance.
Accuracy: The accuracy of the training data is paramount, as inaccurate or biased data will inevitably lead to inaccurate or biased model outputs. This has direct implications for fairness and can lead to discriminatory outcomes. A critical consideration is that inferences generated by an AI system about an individual can themselves constitute new personal data. If these inferences reveal sensitive information (e.g., inferring a health condition or political opinion), they are classified as special category data under Article 9, triggering more stringent processing requirements. The tendency of generative AI models to "hallucinate"—producing confident but factually incorrect information—poses a profound and ongoing challenge to the accuracy principle.
Integrity and Confidentiality: Training datasets are often large and may be copied, moved, and stored across various environments (development, testing, production), increasing the risk of unauthorized access or breaches. Robust security measures, including encryption and strict access controls, are essential. Organizations must maintain clear audit trails documenting all movements and storage of personal data to satisfy accountability requirements. The use of privacy-enhancing technologies (PETs) such as pseudonymization or the generation of synthetic data for training can significantly mitigate these security risks.
Deployment and Inference (Use in Production)
This is the stage where the trained model is put into use, for example, as a customer-facing chatbot.
Transparency: When an individual interacts with an AI system, transparency is crucial. Before any personal data is collected, the user must be clearly and proactively informed about the processing. This includes providing information on the purposes of the processing, the types of data collected, the user's rights, and, critically, the existence of any automated decision-making that could significantly affect them. This information should be presented in a layered and easily accessible format, such as an initial disclaimer in the chat interface with a link to a comprehensive privacy policy.
Data Minimisation: In a live environment, the principle of data minimisation must be strictly enforced by design. A chatbot should only request the information that is absolutely necessary to perform its specific function. For instance, a chatbot designed to book appointments might need a name and email address, but it should not ask for a date of birth or home address unless that information is fundamental to the service being provided. Technical measures are key to implementing this, such as defining a "required_fields" schema in the chatbot's architecture, using input fields that mask sensitive data as it is typed, and employing auto-redaction tools to detect and remove unsolicited personal data shared by users in free-text fields.
Monitoring and Retraining
AI systems are not static; they require ongoing monitoring and periodic retraining to maintain performance and adapt to new data.
Storage Limitation: Organizations must establish and enforce clear data retention policies for all personal data processed by the AI system. This includes both the original training datasets and the data collected during the inference stage (e.g., chat transcripts). Once data is no longer necessary for its specified purpose, it must be securely deleted or irreversibly anonymised. Retaining data indefinitely for potential future retraining increases legal risk and is a violation of the storage limitation principle.
Accountability: Compliance is an ongoing process. AI systems must be continuously monitored to ensure they continue to operate fairly, accurately, and securely. The Data Protection Impact Assessment (DPIA) should not be a one-time exercise conducted at the project's outset; it should be treated as a living document, reviewed and updated regularly to reflect any changes in the processing, the system's capabilities, or the identified risks.
The cumulative effect of applying these principles across the AI lifecycle creates a significant architectural pressure. The GDPR's framework inherently discourages the development of monolithic, general-purpose models trained on vast, undifferentiated datasets. The legal risks and compliance burdens associated with such an approach are substantial. Instead, the regulation incentivizes a shift towards more specialized, purpose-driven AI systems. A legally safer and more compliant architectural paradigm involves: first, clearly defining a narrow and specific purpose for the AI; second, meticulously curating a minimal and relevant dataset tailored to that purpose; and third, embedding privacy-enhancing technologies like federated learning or differential privacy from the outset to minimize data exposure. In this way, GDPR compliance ceases to be a mere legal overlay and becomes an active force shaping the very design of AI systems, favoring privacy-centric architectures over data-maximalist ones.
The following table provides a consolidated framework for applying these principles in practice, serving as a practical tool for translating legal theory into an engineering and governance blueprint.
Table 1: GDPR Principles Mapped to the AI Lifecycle
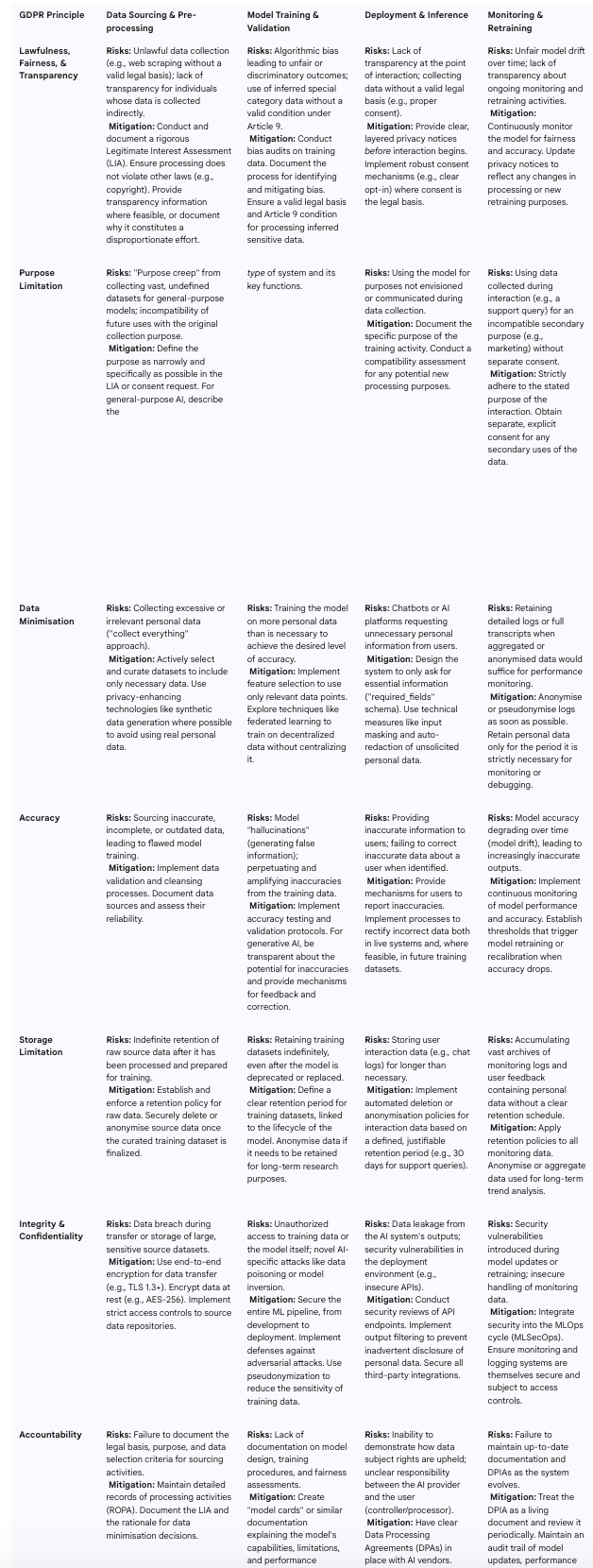
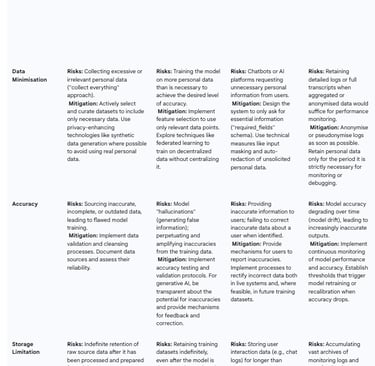
Upholding Individual Rights in Automated Systems
While Part I focused on the obligations of the data controller, the GDPR's ultimate purpose is to empower individuals by granting them a set of fundamental rights over their personal data. For AI and chatbot systems, which can process data at a scale and complexity far beyond traditional applications, providing the means for individuals to exercise these rights is both a significant technical challenge and a legal imperative. This section examines the charter of data subject rights and delves into the specific, and often misunderstood, rules governing automated decision-making.
The Charter of Data Subject Rights
The GDPR codifies a series of rights that allow individuals to maintain control over their personal information. Organizations deploying AI systems must not only be aware of these rights but must also build the necessary technical and organizational infrastructure to facilitate their exercise in a timely and effective manner.
The Right to be Informed (Articles 13 & 14): Individuals have the right to be provided with clear, transparent information about the processing of their personal data. This is a proactive right, meaning the information must be provided at the time of data collection (or within one month if collected indirectly). For AI systems, this information must explicitly state if personal data will be used for model training or to make automated decisions, along with the purposes and legal basis for such processing. A layered approach, with a concise initial notice and a link to a more detailed policy, is often recommended.
The Right of Access (Article 15): Data subjects have the right to obtain confirmation as to whether their personal data is being processed and, if so, to access that data along with supplementary information (such as purposes, recipients, and retention periods). This is commonly exercised through a Data Subject Access Request (DSAR). For AI, this right can be complex. An individual may request to see the specific data points about them held in a database, and potentially even extracts from the training datasets that were used to build a model, especially if this is necessary to understand how the model affects them. Organizations must have systems in place to locate, collate, and provide this information in an intelligible format.
The Right to Rectification (Article 16): If personal data is inaccurate or incomplete, individuals have the right to have it corrected. This is particularly critical for AI systems, where inaccurate input data can lead to flawed and potentially harmful outputs. Organizations need mechanisms, such as a user dashboard or a dedicated contact point, to allow individuals to request corrections. The challenge extends to updating this information not only in primary databases but also in any datasets earmarked for future model retraining.
The Right to Erasure ('Right to be Forgotten') (Article 17): Individuals have the right to have their personal data deleted under certain circumstances, such as when the data is no longer necessary for its original purpose, consent is withdrawn, or the data was processed unlawfully. This right presents one of the most significant technical challenges for AI. While deleting a user's record from a customer database is straightforward, erasing their data's influence from a pre-trained model can be extraordinarily difficult, often requiring partial or complete retraining of the model. If an organization cannot fulfill an erasure request for technical reasons, it must still respond to the individual and clearly explain why the request cannot be met.
The Right to Restrict Processing (Article 18): In certain situations, an individual can request that their data be stored but not otherwise processed. This might be exercised, for example, while the accuracy of their data is being contested. During the restriction period, the data should be effectively quarantined within the system to prevent its use in any active processing, including AI-driven analysis or decision-making.
The Right to Data Portability (Article 20): This right allows individuals to obtain and reuse their personal data for their own purposes across different services. It applies only when the processing is based on consent or contract and is carried out by automated means. The data must be provided in a "structured, commonly used and machine-readable format" (e.g., CSV, JSON, XML). For AI platforms, this could mean allowing a user to download their interaction history or profile data in a portable format.
The Right to Object (Article 21): Individuals have the right to object to processing based on legitimate interests or the performance of a task in the public interest. The organization must then stop processing unless it can demonstrate "compelling legitimate grounds" that override the individual's interests, rights, and freedoms. For direct marketing purposes, the right to object is absolute, and processing must cease immediately upon request. Organizations using personal data to train AI models under the basis of legitimate interests must provide a clear and accessible mechanism for individuals to opt out of this processing.
Organizations must respond to any of these requests without undue delay and at the latest within one month of receipt. This period can be extended by two further months where necessary for complex requests, but the individual must be informed of the extension and the reasons for it within the first month.
The practical implementation of these rights within AI systems creates a powerful feedback mechanism that reinforces core GDPR principles. For example, an organization that trains its models on vast, indiscriminately collected personal data will face immense technical and financial burdens when trying to honor erasure or rectification requests. The sheer difficulty and cost of finding and removing an individual's data from a complex model incentivizes a more responsible approach from the outset. A rational organization, anticipating these future operational costs, is more likely to adhere to the principles of Data Minimisation and Privacy by Design, collecting less personal data in the first place to reduce the scope and complexity of future data subject requests. In this way, the rights are not merely reactive remedies for individuals but also serve as a proactive compliance driver for organizations.
The Challenge of Automated Decision-Making and Profiling (Article 22)
Article 22 of the GDPR is one of the few provisions that directly addresses the outputs of automated systems, making it critically important for the deployment of sophisticated AI. It establishes a qualified right for individuals not to be subject to decisions that have a significant impact on them when those decisions are made without meaningful human involvement.
Scope and Threshold of Article 22
The right under Article 22(1) applies to decisions that are:
Based solely on automated processing: This means the decision is made by technological means without any meaningful human intervention. A human who merely applies the automated decision without any genuine influence or ability to change the outcome does not constitute meaningful intervention.
Including profiling: Profiling is defined as any form of automated processing used to evaluate personal aspects to analyze or predict behavior, preferences, or other characteristics. AI systems used for tasks like credit scoring, risk assessment, or personalized pricing are engaged in profiling.
Which produces legal effects concerning the individual or similarly significantly affects them: This sets a high threshold for the right to apply.
Legal effects refer to decisions that impact someone's legal rights, such as the termination of a contract, the denial of a social benefit, or a decision on border entry.
Similarly significant effects are decisions that have an equivalent impact on an individual's circumstances, behavior, or choices. Examples include the automatic refusal of an online credit application, e-recruiting practices that filter candidates without human review, or significant price differentiation based on profiling.
Exceptions to the Prohibition
The prohibition on solely automated decision-making is not absolute. Such processing is permitted under three specific exceptions outlined in Article 22(2):
Contractual Necessity: The decision is necessary for entering into, or the performance of, a contract between the individual and the controller.
Legal Authorisation: The processing is authorized by Union or Member State law, which must also include suitable safeguards for the individual's rights.
Explicit Consent: The individual has given their explicit consent to the automated decision-making.
Mandatory Safeguards
Crucially, even when one of these exceptions applies, the controller is not absolved of responsibility. Article 22(3) mandates that the controller must implement suitable measures to safeguard the data subject's rights, freedoms, and legitimate interests. At a minimum, these safeguards must include:
The right to obtain human intervention: The individual must have a simple way to request a review of the automated decision by a human.
The right to express their point of view: The individual must be able to present their case and provide additional context or information that may not have been considered by the algorithm.
The right to contest the decision: The individual has the right to challenge the outcome of the automated process.
Furthermore, decisions falling under these exceptions cannot be based on special categories of personal data (e.g., health data, racial or ethnic origin) unless the stringent conditions of Article 9(2) are met, such as obtaining explicit consent or for reasons of substantial public interest, and suitable safeguards are in place.
The requirement for "meaningful human intervention" presents a significant operational and organizational challenge that strikes at the heart of the efficiency gains promised by automation. This is not a superficial, "rubber-stamping" exercise. For the intervention to be meaningful, the human reviewer must have the genuine authority, the necessary competence and training, and access to all relevant information to properly re-evaluate the decision and override the AI's output if necessary.
This creates an operational paradox. Consider an AI system that processes thousands of insurance claims per hour. If the human review process is thorough enough to be considered "meaningful" under the GDPR, it may require a significant investment in trained staff and slow down the process to the point where the primary benefits of automation—speed and cost reduction—are substantially diminished. Conversely, if the review is too cursory to save time and resources, it will fail to meet the legal standard, exposing the organization to compliance risk. Therefore, organizations deploying systems that fall under Article 22 must make a substantial investment in the human side of the equation: designing user interfaces that provide reviewers with interpretable information about the AI's decision, providing comprehensive training on the system's logic and limitations, and establishing clear governance structures that empower human judgment to overrule the machine. This effectively reframes "automation" under the GDPR not as a replacement for human decision-making, but as a form of "human-in-the-loop automation," a far more resource-intensive and carefully governed model than pure, unchaperoned automation.
The "Right to an Explanation": Myth vs. Reality
A common misconception surrounding AI and the GDPR is the existence of a broad "right to an explanation," which would entitle an individual to a detailed breakdown of how and why an algorithm reached a specific decision about them. The reality of the regulation is more nuanced.
The GDPR does not, in fact, establish a standalone or explicit "right to an explanation" in the way it is often portrayed. This interpretation oversimplifies the legal text and creates unrealistic expectations about the explainability of complex "black box" AI models.
What the GDPR does require is rooted in the principles of transparency and the safeguards under Article 22. Specifically, Articles 13, 14, and 15 require controllers to provide data subjects with "meaningful information about the logic involved, as well as the significance and the envisaged consequences of such processing".
In practice, this is widely interpreted to mean that an organization must provide a general understanding of how the automated system works, rather than a detailed technical exposition of the algorithm's internal workings or the specific weighting of every variable for a single decision. For example, in the case of a loan application denied by an automated system, the "meaningful information" would likely include:
An explanation that the decision was made automatically.
The main factors or criteria the algorithm considers (e.g., credit score, income, existing debt, employment history).
The specific input data related to the applicant that was used in the decision.
The significance and potential consequences (e.g., the denial of the loan and its potential impact on credit rating).
This level of explanation is not intended to reverse-engineer the AI model but to provide the individual with enough information to understand the basis of the decision and to meaningfully exercise their rights to express their point of view and contest the outcome, as guaranteed by the safeguards in Article 22. The goal is to empower the individual to have an informed discussion with the human reviewer, not to audit the model's code. Therefore, the focus should be on providing actionable transparency, not absolute technical transparency.
Governance, Risk, and Security by Design
Compliance with the GDPR is not a retroactive exercise; it demands a proactive and preventative approach to data protection. This part of the report focuses on the concrete governance frameworks, risk assessment methodologies, and technical security measures that organizations must implement from the ground up when developing and deploying chatbots and AI platforms. These elements are not optional additions but are mandated by the GDPR to ensure that privacy is a foundational component of any data processing system.
Data Protection by Design and by Default (Article 25)
Article 25 of the GDPR codifies the principles of "Data Protection by Design" and "Data Protection by Default," transforming them from best practices into legal obligations. This framework requires organizations to build data protection measures directly into the architecture of their processing systems from the earliest stages of design, rather than treating privacy as an afterthought or a "bolt-on feature".
Core Principles of Privacy by Design (PbD)
The concept of Privacy by Design is based on seven foundational principles, which are highly relevant to the development of trustworthy AI :
Proactive not Reactive; Preventative not Remedial: This principle mandates anticipating and preventing privacy risks before they can materialize, rather than waiting for a data breach or compliance failure to occur.
Privacy as the Default Setting: Systems should be configured to be privacy-protective by default, without requiring any action from the user. This means the highest level of privacy protection is the standard setting, and individuals must actively choose to lessen it.
Privacy Embedded into Design: Privacy safeguards must be an integral component of the system's core architecture and functionality, not a separate feature.
Full Functionality—Positive-Sum, not Zero-Sum: PbD seeks to accommodate all legitimate interests and objectives, demonstrating that it is possible to achieve both privacy and innovation without a trade-off.
End-to-End Security—Lifecycle Protection: Data must be securely protected throughout its entire lifecycle, from collection to secure destruction.
Visibility and Transparency: The systems and practices must be transparent, allowing stakeholders to verify that the privacy promises are being met.
Respect for User Privacy—Keep it User-Centric: The design should be centered on the interests and rights of the individual, offering strong privacy defaults, clear notices, and user-friendly controls.
Implementation in AI Systems
Translating these principles into the context of AI development requires a deliberate and strategic approach:
Adherence to Data Minimisation and Purpose Limitation: These GDPR principles are the practical embodiment of PbD in AI. At the outset of any AI project, developers must rigorously define the specific purpose and collect only the data that is strictly necessary to achieve it, resisting the temptation to "collect now, decide later".
Leveraging Privacy-Enhancing Technologies (PETs): PbD encourages the active integration of technologies that minimize personal data exposure while preserving data utility. For AI, key PETs include:
Differential Privacy: A technique that adds a carefully calibrated amount of statistical "noise" to data outputs, making it mathematically difficult to determine whether any single individual's data was part of the dataset, thus protecting privacy in aggregate analyses.
Federated Learning: A decentralized machine learning approach where the model is trained on local data across multiple devices (e.g., mobile phones) without the raw data ever leaving the device. Only the aggregated model updates are sent to a central server, significantly reducing the risks associated with central data aggregation.
Homomorphic Encryption: An advanced cryptographic method that allows for computations to be performed directly on encrypted data, meaning data can be processed and analyzed without ever being decrypted.
Pseudonymisation and Anonymisation: Applying these de-identification techniques as early as possible in the data processing pipeline to reduce the sensitivity of the data being used for training and analysis.
Real-World Examples and Case Studies
The strategic importance of PbD is best illustrated by real-world examples:
Positive Implementations:
Apple has built a significant part of its brand identity around privacy. The company extensively uses on-device processing for features like facial recognition and predictive text, ensuring sensitive personal data remains on the user's device. Where data is sent to Apple's servers for analysis, it often employs differential privacy to protect individual identities.
Google utilizes federated learning in its Gboard keyboard for Android. The system improves predictive text suggestions by learning from what users type directly on their phones, without sending the actual text to Google's servers. This allows the model to benefit from real-world usage data while respecting user privacy.
Cautionary Tales:
Clearview AI and Cambridge Analytica serve as stark reminders of the consequences of ignoring privacy by design. Clearview AI's practice of scraping billions of facial images from the internet without consent to build a facial recognition database led to global regulatory action, fines, and severe reputational damage. Similarly, Cambridge Analytica's harvesting of Facebook user data for political profiling resulted in a massive public trust crisis and significant legal repercussions.
In today's data-driven economy, where consumer trust is a fragile and valuable asset, Privacy by Design is evolving from a mere legal obligation into a strategic business imperative. The growing public and regulatory scrutiny of AI means that user trust is a critical factor for the adoption and success of new technologies. Organizations that authentically embed privacy into the core of their AI products—demonstrating transparency, user-centricity, and robust security by default—are better positioned to win that trust. This can translate directly into a tangible competitive advantage, leading to higher adoption rates, greater brand loyalty, and a more sustainable market position. In this context, privacy ceases to be a compliance cost center and becomes a key driver of business value.
Conducting a Data Protection Impact Assessment (DPIA) for AI Systems
A Data Protection Impact Assessment (DPIA) is a systematic process mandated by Article 35 of the GDPR to identify, assess, and mitigate data protection risks associated with processing activities that are "likely to result in a high risk to the rights and freedoms of natural persons". Given their complexity, scale, and potential for significant impact on individuals, AI systems almost invariably trigger the requirement to conduct a DPIA before processing begins.
When is a DPIA Required for AI?
A DPIA is mandatory if the AI processing involves, among other criteria:
Systematic and extensive evaluation of personal aspects (profiling) that forms the basis for decisions producing legal or similarly significant effects.
Processing on a large scale of personal data, and especially of special categories of data or data relating to criminal convictions.
The use of new or innovative technologies, where the consequences for individuals may not be fully understood.
Virtually all non-trivial AI applications, from chatbots processing customer data at scale to machine learning models used for recruitment or credit scoring, will meet one or more of these criteria, making a DPIA a standard and essential step in the AI development lifecycle.
A Step-by-Step Guide to Conducting an AI-Specific DPIA
While the core steps of a DPIA are standardized, an assessment for an AI system must incorporate specific considerations related to the unique risks of the technology.
Step 1: Identify the Need and Define the Project Overview: Begin by formally documenting why a DPIA is necessary, referencing the high-risk criteria. Provide a clear, high-level overview of the AI project's objectives, its importance to the organization, and how personal data is central to its function.
Step 2: Describe the Processing Operations: This step requires a systematic and detailed mapping of the data flows and processing activities throughout the AI lifecycle. The documentation should include:
Nature: The types of data to be collected (including any special categories), the methods of collection (e.g., user input, web scraping), and the technologies used (e.g., specific algorithms, cloud infrastructure).
Scope: The volume of data, the number of individuals affected, the geographical area covered, and the data retention periods for all datasets (raw, training, and inference).
Context: The relationship with the data subjects, their reasonable expectations, and any power imbalances that may exist.
Purpose: The specific, explicit, and legitimate purposes for the processing, including the intended benefits for the organization and for individuals.
Step 3: Consultation Process: The GDPR requires consultation with relevant stakeholders. This must include the organization's Data Protection Officer (DPO). Depending on the context, it may also be appropriate to consult with IT and cybersecurity teams, external privacy experts, and, where feasible, the data subjects themselves or their representatives to understand their views and concerns.
Step 4: Assess Necessity and Proportionality: This step involves justifying the processing in relation to its purpose. The assessment must confirm that there is a valid lawful basis for the processing and that the AI system is a necessary and proportionate way to achieve the stated goals. It should consider whether less privacy-intrusive alternatives exist and how the principles of data minimisation and purpose limitation are being upheld.
Step 5: Identify and Assess Risks to Individuals: This is the core of the DPIA. The team must systematically identify the potential risks to the rights and freedoms of individuals that may arise from the AI system. For AI, these risks extend beyond traditional data breaches and include :
Inaccuracy and Errors: Risks from the model producing incorrect outputs or "hallucinations."
Bias and Discrimination: The risk of the AI system producing biased decisions that lead to unfair or discriminatory treatment of certain individuals or groups.
Lack of Transparency and Explainability: The risk that individuals cannot understand or challenge decisions made about them due to the "black box" nature of the model.
Re-identification: The risk that pseudonymised or anonymised data could be re-identified.
Security Vulnerabilities: Risks from AI-specific attacks like data poisoning or model inversion. For each identified risk, its likelihood and severity must be assessed to determine an overall risk level (e.g., low, medium, high).
Step 6: Identify Measures to Mitigate Risks: For each risk identified (particularly those assessed as medium or high), the DPIA must outline specific measures to mitigate it. These can be technical measures (e.g., implementing bias detection algorithms, using differential privacy, enhancing encryption) or organizational measures (e.g., establishing human oversight procedures, providing specific training to staff, creating clear transparency notices for users). The DPIA should document how each measure reduces the specific risk and what the residual risk level is after implementation.
If, after implementing mitigation measures, the DPIA identifies a residual high risk, Article 36 of the GDPR requires the organization to consult with the relevant supervisory authority before commencing the processing. The DPIA is not a static document; it must be regularly reviewed and updated to reflect any changes in the AI system or the data processing environment, making it a critical tool for ongoing governance and accountability.
Technical and Organisational Measures for Securing AI (Article 32)
Article 32 of the GDPR obligates controllers and processors to implement "appropriate technical and organisational measures" (TOMs) to ensure a level of security appropriate to the risk posed by the processing. This is a risk-based and technologically neutral requirement, meaning there is no one-size-fits-all checklist. The appropriateness of the measures depends on the state of the art, the costs of implementation, and the nature, scope, context, and purposes of the processing. For AI systems, which often process vast amounts of data and present novel security challenges, a robust and multi-layered security posture is essential.
Standard Technical and Organisational Measures
Many of the TOMs required for AI systems are foundational cybersecurity best practices:
Organisational Measures: These include developing internal security policies, providing regular data protection training to employees, implementing information classification policies, and establishing clear incident response plans. A critical organizational measure is robust access control, ensuring that only authorized personnel can access personal data based on the principle of least privilege. This involves using role-based permissions, unique user identifiers (no shared accounts), and prompt removal of access for departing staff.
Physical Security: Securing the physical infrastructure where data is processed and stored, such as servers and data centers, through measures like access controls, alarms, and environmental protections.
Network and System Security: Implementing firewalls, regularly updated antivirus software, automatic security patching, and secure configuration of all hardware and software components.
Technical Implementation of Pseudonymisation and Encryption in AI/ML Pipelines
Pseudonymisation and encryption are explicitly mentioned in Article 32 as examples of appropriate technical measures and are particularly crucial for securing AI/ML pipelines.
Pseudonymisation: This de-identification technique involves replacing direct identifiers (like name or email address) with artificial identifiers or "tokens". While the data is still personal data (as re-identification is possible with a separate key), it significantly reduces risk by obfuscating the raw sensitive identifiers. In AI/ML pipelines, pseudonymization allows data scientists to train models and perform analytics on datasets without having direct access to the identifiable information.
Techniques: Common methods include cryptographic tokenization, which uses an encryption algorithm to generate the token. This can be done via:
Deterministic Encryption (e.g., AES-SIV): This method is reversible, meaning the original data can be recovered with the correct key. It produces a hashed value, preserving referential integrity (the same input always produces the same token) but not the original format.
Format-Preserving Encryption (FPE): This reversible technique encrypts data in a way that the output token has the same format and length as the original input, which can be useful for legacy systems.
Cryptographic Hashing (e.g., HMAC-SHA-256): This is an irreversible (one-way) method that produces a fixed-length hash. It is useful when there is no need to ever re-identify the data.
Encryption: This is a fundamental security control for protecting data throughout its lifecycle within an AI system.
Encryption in Transit: All data moving between systems—from the user's device to the chatbot server, or between different microservices in the cloud—must be encrypted using strong protocols like HTTPS and TLS 1.3+.
Encryption at Rest: All personal data stored in databases, file systems, or backups must be encrypted using robust algorithms like AES-256.
Secure Key Management: The security of encrypted data is entirely dependent on the security of the encryption keys. Best practices demand the use of a dedicated Key Management Service (KMS), such as those offered by cloud providers, to create, store, manage, and rotate keys securely. Keys should never be hard-coded in applications or stored alongside the data they protect.
Addressing AI-Specific Security Threats
In addition to standard security measures, organizations must address a new class of vulnerabilities unique to machine learning systems. A comprehensive security strategy for AI must account for these adversarial threats:
Data Poisoning: This attack occurs during the training phase, where an adversary intentionally injects malicious or mislabeled data into the training set. The goal is to corrupt the model, causing it to make incorrect predictions or create a "backdoor" that the attacker can later exploit. Mitigation involves strict controls over training data sources, data validation, and anomaly detection.
Model Inversion and Membership Inference: These are privacy attacks that aim to extract sensitive information from a trained model.
Membership Inference attempts to determine whether a specific individual's data was used to train the model.
Model Inversion goes further, attempting to reconstruct parts of the training data (e.g., an individual's face from a facial recognition model) by repeatedly querying the model. Mitigation techniques include differential privacy, which adds noise to make such inferences more difficult, and reducing the model's output granularity.
Adversarial Attacks (Evasion Attacks): These attacks happen at the inference stage. An attacker crafts a carefully designed input that is subtly modified to fool the model into making an incorrect classification. For example, a tiny, human-imperceptible change to an image could cause an object recognition system to misidentify it completely. Defenses include adversarial training (exposing the model to such examples during training) and input sanitization.
A holistic approach to AI security, often referred to as MLSecOps, involves integrating these security considerations into every stage of the machine learning lifecycle, from data ingestion and model development to deployment and ongoing monitoring.
The New Frontier - Generative AI and Evolving Regulations
The rapid proliferation of Generative AI, particularly Large Language Models (LLMs), has introduced a new paradigm of data processing that strains the existing framework of the GDPR in unprecedented ways. These models present a class of privacy risk that is fundamentally different and more severe than that of traditional analytical AI. This final part of the report provides a comparative analysis of these risks and examines the current regulatory landscape, synthesizing guidance from key data protection authorities and highlighting enforcement trends that signal the future direction of AI governance in Europe.
Section 9: Generative vs. Analytical AI: A Comparative Risk Analysis
To understand the unique challenges posed by Generative AI, it is essential to contrast it with traditional analytical AI.
Analytical AI typically refers to models designed for specific predictive or classification tasks. For example, an analytical model might be used for credit scoring, identifying fraudulent transactions, or predicting customer churn. These systems are generally trained on structured, curated datasets to learn patterns and make inferences. While they carry significant privacy risks related to fairness, accuracy, and automated decision-making, the scope of their data processing is usually well-defined and more easily aligned with GDPR principles like purpose limitation and data minimisation. The output of an analytical model is typically an inference (e.g., a score, a category), not a recreation of its training data.
Generative AI, by contrast, is designed to create new content that mimics the data on which it was trained. This creative or synthetic capability is the source of its most profound and novel privacy risks, which amplify the challenges seen in analytical AI across several dimensions:
Unprecedented Scale and Indiscriminate Sourcing of Data: While analytical AI often uses targeted datasets, foundational LLMs are frequently trained by scraping vast, unstructured portions of the public internet. This practice makes it practically impossible to establish a valid lawful basis for every piece of personal data collected, to provide transparency notices to all affected individuals, or to adhere strictly to the purpose limitation principle, as the data is collected for a general, open-ended purpose.
Data Memorization and Uncontrolled Regurgitation: Analytical models learn statistical patterns. Generative models, due to their immense size and complexity, can go a step further and "memorize" specific, unique pieces of information from their training data, including personal stories, contact details, or sensitive information. The critical risk is that a model might later "regurgitate" this memorized personal data in response to an unrelated prompt from a different user, leading to an unexpected and uncontrolled data breach.
Fundamental Challenge to Accuracy and Rectification: Generative models are known to "hallucinate," creating highly plausible but entirely false information about real individuals. This directly conflicts with the accuracy principle (Article 5(1)(d)). Furthermore, when a model generates such false information, exercising the right to rectification becomes immensely challenging. Correcting the "fact" in one instance does not prevent the model from generating it again, and removing the source of the inaccuracy from the model's parameters is a non-trivial technical problem.
Practical Unenforceability of Data Subject Rights: The very architecture of large generative models makes fulfilling certain data subject rights, particularly the right to erasure, technically difficult, if not impossible. An individual's personal data is not stored in a discrete, deletable record but is encoded as part of the model's millions or billions of mathematical parameters. Removing the influence of a single individual's data may require retraining the entire model at a prohibitive cost, rendering the right to be forgotten practically unenforceable.
Dual Role of User Input: In many generative AI applications, the user's input (the "prompt") can contain personal data. This input is not only used to generate an immediate output but may also be retained and used by the AI provider for further model training. This creates complex questions about the legal basis for this secondary processing and can establish a joint controllership relationship between the user and the AI provider, with significant liability implications.
The core distinction in risk profiles stems from the model's fundamental function. Analytical AI infers from data to produce a decision or a score; the privacy risk is primarily concentrated in the consequences of that inference. Generative AI, however, recreates and synthesizes data; its function is to generate new content that reflects its training data. This recreative capability means the training data is not just a means to an end but is also a potential, latent output. This transforms the model itself into a massive, unstructured, and potentially uncontrollable repository of personal information, fundamentally escalating the risks of data leakage and making core GDPR principles like storage limitation and erasure almost theoretically impossible to apply with perfect fidelity.
Section 10: Regulatory Landscape and Enforcement Trends
The challenges posed by AI, and generative AI in particular, have not gone unnoticed by European data protection authorities (DPAs). A consensus is forming around key areas of concern, and enforcement actions, though still in their early stages, are beginning to outline the boundaries of acceptable practice.
Guidance from Key European Data Protection Authorities
The European Data Protection Board (EDPB): As the collective body of EU DPAs, the EDPB's guidance is highly influential. In its recent opinions, the EDPB has emphasized:
A High Bar for Anonymisation: An AI model trained on personal data can only be considered truly "anonymous" (and thus outside the scope of the GDPR) if the controller can demonstrate that the likelihood of re-identifying an individual from the model is "insignificant". The EDPB recognizes that personal data can become "absorbed" into the model's parameters, placing a heavy burden of proof on developers to demonstrate robust anonymisation.
Scrutiny of "Legitimate Interests": While acknowledging that "legitimate interests" is a potential legal basis for processing data for AI training, the EDPB insists on a rigorous, documented balancing test. This test must carefully consider the reasonable expectations of data subjects and the potential benefits of the processing, with a strong emphasis on providing clear opt-out mechanisms.
Prioritization of AI Governance: The EDPB is actively developing training materials and guidance on AI, signaling that it is a high-priority area for coordinated regulatory attention across the EU.
The UK Information Commissioner's Office (ICO): The ICO's position largely aligns with the EDPB's, with a particular focus on:
Transparency and Fairness: The ICO stresses the need for transparency regarding model accuracy and the use of inferred data. It has also stated that simply because data is publicly accessible does not mean individuals have a reasonable expectation that it will be used to train complex AI models.
Mandatory DPIAs: The ICO considers most AI-related processing to be high-risk, making a thorough DPIA a non-negotiable prerequisite.
Dynamic Guidance: The ICO is continuously reviewing and updating its AI guidance in response to new technologies and legislation, indicating a fluid and evolving regulatory environment.
Enforcement Actions and Emerging Priorities
Regulatory actions are beginning to provide concrete examples of how DPAs will enforce the GDPR in the context of AI:
Procedural Compliance is Key: The ICO's investigation into Snap's "My AI" chatbot is instructive. While the ICO ultimately did not issue an enforcement notice, its initial action was triggered by concerns that Snap had not conducted an adequate DPIA before launch. Snap's subsequent completion of a revised, compliant DPIA resolved the matter. This demonstrates that DPAs are focused on procedural requirements; a failure to properly assess risk via a DPIA is, in itself, an enforcement trigger.
Focus on Lawful Basis and Transparency: The Italian DPA's (Garante) temporary suspension of ChatGPT in 2023 was a landmark action. The Garante cited a lack of a valid legal basis for the mass collection of data for training and insufficient transparency for users as primary concerns. This signaled a clear willingness among national DPAs to take decisive action against even the largest AI providers.
Protection of Vulnerable Groups: Complaints filed with the ICO regarding the UK Home Office's use of algorithms in immigration enforcement highlight another area of regulatory concern. The allegations focus on breaches of fairness and transparency and the potential for discriminatory impacts on a vulnerable population, indicating that the use of AI in high-stakes public sector decision-making will be subject to intense scrutiny.
The Interplay with the EU AI Act
The regulatory landscape is further shaped by the landmark EU AI Act, which complements, but does not replace, the GDPR. The AI Act establishes a risk-based framework for AI systems, but it explicitly states that the GDPR continues to apply in full whenever personal data is processed.
There is significant overlap in their core principles. Concepts central to the AI Act, such as fairness, transparency, accountability, and the need for human oversight, are directly mirrored in the GDPR's requirements. For organizations, this means that robust GDPR compliance is a foundational and non-negotiable first step toward readiness for the AI Act. A well-executed DPIA under the GDPR, for example, will address many of the risk assessment and fairness considerations required for high-risk systems under the AI Act.
Conclusion
The application of the General Data Protection Regulation to chatbots and AI platforms is not a simple matter of legal interpretation but a complex challenge that lies at the intersection of law, ethics, and technology. The principles-based, technologically neutral framework of the GDPR, while robust, is being tested by the scale, opacity, and novel capabilities of modern AI.
Our analysis reveals several critical conclusions for organizations operating in this domain:
GDPR as an Architectural Force: The core principles of the GDPR—particularly purpose limitation, data minimisation, and storage limitation—exert a powerful architectural pressure on AI development. They actively discourage the data-maximalist approach of building monolithic, general-purpose models on indiscriminately sourced data. Instead, the path of least legal resistance leads toward the development of more specialized, purpose-driven AI systems that are designed from the outset with privacy in mind.
Accountability as the Linchpin of Compliance: In the face of "black box" algorithms where demonstrating fairness or the absence of bias can be technically challenging, the GDPR's accountability principle becomes paramount. Meticulous documentation—through robust Data Protection Impact Assessments, Legitimate Interest Assessments, and Records of Processing Activities—is not merely a bureaucratic exercise. It is the primary mechanism through which an organization can demonstrate its compliance to regulators and build a defensible legal position.
Data Subject Rights as a Proactive Compliance Driver: The technical and operational challenges of honoring data subject rights, especially the rights to erasure and rectification in the context of trained AI models, create a powerful incentive for responsible data stewardship. The anticipated cost and complexity of fulfilling these rights should compel organizations to adopt data minimisation and Privacy by Design as a core strategy, thereby reducing their compliance surface area from the very beginning.
Generative AI as a Paradigm Shift in Risk: Generative AI introduces a new category of privacy risk that is qualitatively different from that of traditional analytical AI. Its ability to memorize and regurgitate personal data, generate convincing falsehoods, and render individual rights practically unenforceable presents a profound challenge to the GDPR framework. This heightened risk profile demands a commensurately higher standard of care, governance, and technical safeguards.
A Proactive, Risk-Based Approach is Non-Negotiable: The clear trajectory of regulatory guidance and enforcement actions indicates that a passive or reactive approach to compliance is untenable. Organizations must embrace a proactive posture, embedding Privacy by Design into their development lifecycles, conducting rigorous and ongoing risk assessments through DPIAs, and implementing robust technical and organizational security measures tailored to AI-specific threats.
Navigating this complex landscape requires a multidisciplinary approach, where legal and compliance teams work in close collaboration with data scientists, engineers, and business leaders. The GDPR should not be viewed as a barrier to innovation, but as a framework for responsible innovation—one that ensures the development of AI systems that are not only powerful and effective but also trustworthy, ethical, and respectful of the fundamental right to data protection. As AI technology continues to evolve, the organizations that succeed will be those that treat privacy not as a compliance hurdle, but as a core component of their design philosophy and a key pillar of user trust.