Impact of GDPR on AI in the Healthcare Industry
This article examines the profound and often paradoxical impact of the European Union's General Data Protection Regulation (GDPR) on the development and deployment of Artificial Intelligence (AI) in the healthcare sector.
Staff


This article examines the profound and often paradoxical impact of the European Union's General Data Protection Regulation (GDPR) on the development and deployment of Artificial Intelligence (AI) in the healthcare sector. It articulates a central tension: GDPR, a landmark regulation designed to protect the fundamental right to data privacy, creates significant friction with the data-intensive operational requirements of AI, a technology poised to revolutionize medical diagnostics, treatment, and research.
The analysis reveals that core GDPR principles—notably data minimisation, purpose limitation, and the high standard for explicit consent—pose formidable challenges to AI development, which thrives on vast, diverse datasets to achieve accuracy, fairness, and novel discoveries. These legal constraints are in direct opposition to the "big data" paradigm that fuels modern machine learning. Furthermore, the report dissects the contentious "right to explanation" for automated medical decisions under Article 22, highlighting the deep chasm between this legal ideal and the technical reality of complex "black box" algorithms, whose internal logic is often opaque even to their creators.
Conversely, this report argues that GDPR is more than a regulatory hurdle; it is a powerful catalyst for progress. The regulation's stringent requirements are spurring innovation in a new class of Privacy-Enhancing Technologies (PETs), such as federated learning, differential privacy, and synthetic data generation. These technologies offer pathways to reconcile the demands of data protection with the needs of AI. More fundamentally, GDPR provides an essential framework for building patient trust, a non-negotiable prerequisite for the long-term adoption and social acceptance of AI in medicine. By mandating a "Privacy by Design" approach, GDPR is fostering a market for more secure, ethical, and robust AI solutions, establishing a global benchmark for responsible innovation.
Looking forward, the emerging regulatory landscape, anchored by the new EU AI Act, will create a multi-layered governance ecosystem alongside GDPR and the Medical Device Regulation (MDR). This will further solidify the EU's position as a leader in trustworthy AI but will also intensify the compliance challenges for stakeholders. This report concludes with strategic recommendations for policymakers, healthcare providers, and AI developers to navigate this complex terrain, fostering an environment where privacy and progress are not mutually exclusive but are mutually reinforcing pillars of the future of healthcare.
The Regulatory and Technological Landscape
This section establishes the foundational context for the report by examining the two central forces at play: the comprehensive legal framework of the GDPR and the transformative technological paradigm of AI in healthcare. It provides the necessary legal and technical primers to understand their intricate and often conflicting interaction.
1.1. GDPR's Core Mandates for Health Data: A Legal Primer
The GDPR establishes a robust and principles-based framework for data protection. Its application to the healthcare sector is particularly stringent due to the sensitive nature of the information involved.
Defining "Personal Data" and "Special Category Data" Under the GDPR, health data, genetic data, and biometric data are classified as "special categories of personal data". This designation affords them a higher level of protection than standard personal data, meaning their processing is prohibited unless specific, explicit conditions are met, such as obtaining explicit consent from the data subject or for reasons of substantial public interest in the area of public health. This classification is the legal bedrock for all AI applications in healthcare, significantly elevating the compliance burden.
The Seven Key Principles of Data Protection The processing of all personal data, and especially health data, is governed by seven core principles articulated in Article 5 of the GDPR :
Lawfulness, Fairness, and Transparency: Processing must have a valid legal basis, must not be unduly detrimental or misleading to individuals, and organizations must be clear and honest about how they use data.
Purpose Limitation: Data must be collected for "specified, explicit, and legitimate purposes" and not be further processed in a manner that is incompatible with those purposes. This principle creates an immediate tension with the exploratory and evolving nature of AI research.
Data Minimisation: The personal data collected must be "adequate, relevant, and limited to what is necessary" for the stated purpose. This is in direct conflict with the data-hungry nature of many advanced machine learning models.
Accuracy: Data must be accurate and, where necessary, kept up to date. Every reasonable step must be taken to erase or rectify inaccurate data without delay.
Storage Limitation: Data must be kept in a form which permits identification of data subjects for no longer than is necessary for the purposes for which the data are processed.
Integrity and Confidentiality (Security): Data must be processed in a manner that ensures appropriate security, including protection against unauthorized or unlawful processing and against accidental loss, destruction, or damage, using "appropriate technical or organisational measures".
Accountability: The data controller is responsible for, and must be able to demonstrate, compliance with all the other principles. This places the onus of proof squarely on the healthcare organization or AI developer, requiring comprehensive documentation and record-keeping.
Data Subject Rights The GDPR empowers individuals with a suite of enforceable rights over their personal data. Healthcare organizations must establish clear processes to facilitate these rights, which include the right of access to their data, the right to rectification of inaccurate data, the right to erasure (the "right to be forgotten"), and the right to object to processing.
A structural difference between GDPR and other major privacy laws, such as the US's HIPAA, is critical to understanding its unique impact. GDPR's principles-based nature makes it adaptable and "future-proof," but it also creates legal ambiguity for novel technologies like AI. Developers are forced to interpret how high-level concepts like "data minimisation" apply to a technology whose operational paradigm was not envisioned when the law was written. This contrasts with more rules-based legislation, which can be more prescriptive but less flexible. Consequently, GDPR compliance for AI is less about checking boxes and more about constructing a defensible, risk-based argument for why a particular data processing activity is lawful—a fundamentally more complex task.
1.2. The AI Revolution in Medicine: Applications and Data Dependencies
Artificial intelligence is poised to trigger a paradigm shift in medicine, moving from a reactive, one-size-fits-all model to a proactive, personalized, and predictive approach. Its potential spans the entire healthcare ecosystem, from diagnostics and treatment to research and administration.
Key AI Applications and Their Data Needs The transformative power of AI is most evident in several key areas:
Medical Imaging Analysis: Deep learning algorithms have demonstrated superhuman capabilities in analyzing medical images such as X-rays, CT scans, and MRIs. They can identify subtle patterns indicative of tumors, fractures, or other pathologies with remarkable precision, often earlier than the human eye. For example, a Google Health AI model demonstrated the ability to detect breast cancer from mammograms more accurately than human radiologists. The development of such models is entirely dependent on access to vast, curated, and accurately labeled datasets of medical images.
Predictive Analytics and Genomics: AI models can sift through complex datasets, including electronic health records (EHRs), genomic sequences, and real-time data from wearable devices, to predict a patient's risk of developing chronic conditions like heart disease or diabetes. This predictive power allows for early intervention but requires large-scale, longitudinal health data from diverse populations to be effective and equitable.
Drug Discovery and Development: AI is dramatically accelerating the traditionally slow and expensive process of drug discovery. By analyzing massive molecular and biological datasets, AI can predict which chemical compounds are most likely to be effective against a particular disease, identify ideal candidates for clinical trials, and streamline post-market safety monitoring.
The Data Imperative A common thread connects all these applications: their performance, reliability, and fairness are directly proportional to the volume, variety, and quality of the data on which they are trained. This fundamental data dependency is the central point of collision with the GDPR's data protection principles. Furthermore, the definition of "health data" under GDPR is expanding beyond the traditional clinical setting. Data from consumer-facing wellness apps and wearable devices, which might fall outside the scope of regulations like HIPAA in the US, are unequivocally considered "special category" health data when collected from an EU citizen. This pulls a wider range of AI technologies into a high-risk regulatory domain, effectively forcing global technology companies to adopt GDPR's high standards as a default for their products.
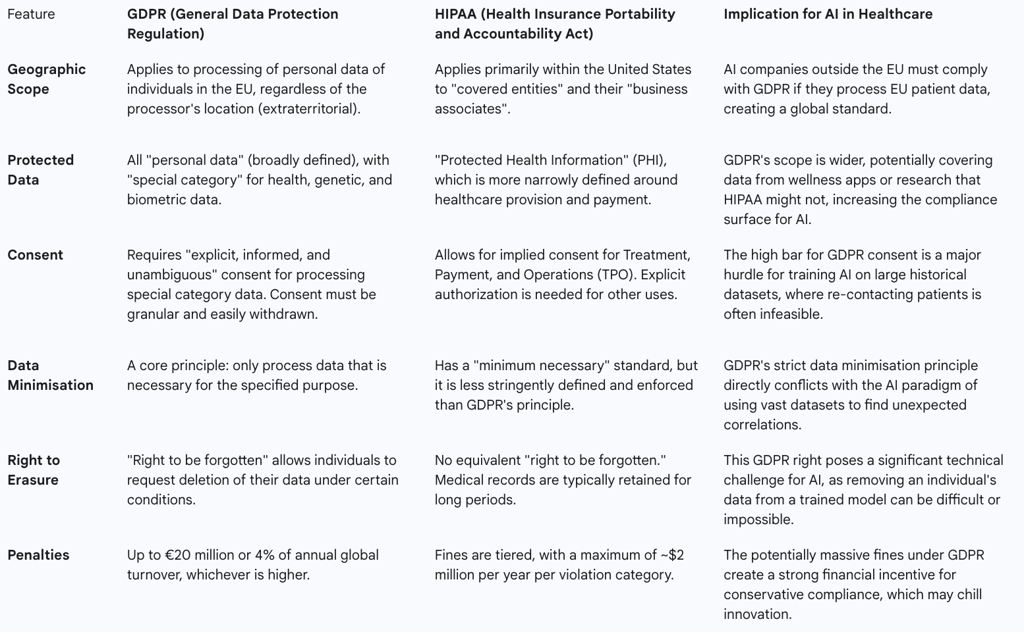
1.3. A Tale of Two Frameworks: A Comparative Overview of GDPR and HIPAA
To fully appreciate the unique stringency of the European approach and its implications for a global AI industry, it is instructive to compare the GDPR with the primary healthcare privacy law in the United States, the Health Insurance Portability and Accountability Act (HIPAA). While both aim to protect patient data, their scope, requirements, and philosophical underpinnings differ significantly, creating a complex compliance landscape for multinational organizations.
Table 1: Comparative Overview of GDPR and HIPAA
The Central Conflict: GDPR's Principles as Hurdles for Healthcare AI
This section dissects the core tensions between the GDPR's foundational data protection principles and the operational requirements of AI systems in healthcare. It moves beyond a description of the rules to an analysis of how these principles create practical, technical, and philosophical conflicts for AI development and deployment.
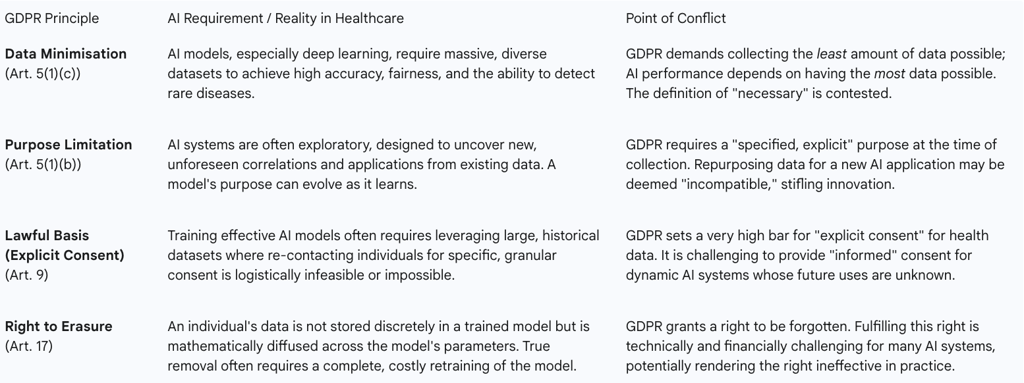
2.1. Data Minimisation vs. The Big Data Paradigm
The principle of data minimisation, which mandates that data collection be "limited to what is necessary" , is in fundamental opposition to the technical reality of modern AI. For many advanced AI models, particularly in the realm of deep learning, performance is a direct function of the quantity and diversity of the training data. Large datasets are not a luxury but a necessity for achieving high levels of accuracy, for identifying the subtle signals of rare diseases, and, crucially, for mitigating algorithmic bias against underrepresented demographic groups.
The GDPR's demand that developers justify every single data point collected is particularly challenging in the context of exploratory AI research. The very purpose of some machine learning projects is to discover which data features are relevant and predictive—a goal that cannot be fully known in advance. The principle, therefore, appears to demand a level of foresight that is antithetical to the inductive, pattern-finding nature of machine learning, creating a significant legal hurdle for innovation. This tension creates a "compliance paradox": a good-faith effort to comply with data minimisation by collecting a smaller, more focused dataset could inadvertently lead to the creation of a biased AI model. An algorithm trained on a non-representative sample may perform poorly for minority groups, leading to discriminatory outcomes and a violation of the GDPR's principle of "Fairness". This means that compliance requires a sophisticated balancing act, often documented through Data Protection Impact Assessments (DPIAs), where organizations must justify why collecting more data is essential to ensure fairness and prevent discrimination, a position that seems to contradict the literal interpretation of the minimisation principle.
2.2. Purpose Limitation in the Face of Evolving AI Models
The purpose limitation principle requires that personal data be collected for "specified, explicit, and legitimate purposes" and not be further processed for incompatible ends. This creates a straitjacket for AI systems, which are often designed to learn, evolve, and uncover unexpected applications. An AI model trained to diagnose one type of cancer from medical images might, for example, reveal an unforeseen capability to detect early signs of a different condition.
Under GDPR, determining whether this new, AI-discovered purpose is "incompatible" with the original purpose of collection is a legal gray area fraught with risk. For instance, patient data collected for the primary purpose of providing clinical treatment could be repurposed to train a commercial AI diagnostic tool sold by a third party. This secondary use is likely far beyond what patients reasonably expected when their data was collected, creating a clear compliance challenge. While the GDPR does provide some flexibility for "scientific or historical research purposes," allowing for a presumption of compatibility, the boundaries of this exemption become blurred in the context of public-private partnerships where commercial and research interests are deeply intertwined.
2.3. The Complexity of 'Explicit Consent' for Dynamic Systems
For processing special category health data, the GDPR's default legal basis is "explicit consent". This consent must be specific, informed, and unambiguous, representing a very high legal bar. The dynamic and evolving nature of AI systems makes meeting this standard exceptionally difficult. A core challenge is obtaining truly "informed" consent for an AI system whose functions and data uses may change over time as the model learns and is updated. It is practically impossible to inform a patient of all potential future research uses of their data at the initial point of collection, especially when those uses have not yet been discovered.
Furthermore, the logistical hurdles are immense. The prospect of obtaining new, granular, explicit consent from millions of individuals whose data resides in historical hospital archives is often practically and financially prohibitive. This effectively locks away vast stores of valuable real-world data that could be used to train the next generation of life-saving AI models, creating a significant barrier to progress.
2.4. The 'Right to be Forgotten' and the Immutability of Trained Models
The GDPR grants data subjects a "right to erasure," also known as the "right to be forgotten," allowing them to request the deletion of their personal data under certain conditions. While straightforward for traditional databases, this right presents a profound technical impasse for trained AI models. An individual's data is not stored as a discrete, removable entry within the model. Instead, the information and patterns from their data have been mathematically absorbed and diffused across the model's millions or even billions of interconnected parameters (or "weights").
Truly removing the influence of a single individual's data would, in most cases, require the entire model to be discarded and retrained from scratch on a dataset that excludes that individual's information. This process is not only computationally intensive but can be prohibitively expensive and time-consuming, rendering meaningful compliance with erasure requests a significant technical and financial challenge. This clash is not merely technical but epistemological; it represents a conflict between a legal framework built on a predictable, linear model of data processing and a technology based on emergent, probabilistic inference. The law assumes data is a "thing" that can be deleted, while the technology encodes the
information from that data into its very structure.
Table 2: GDPR Principles vs. AI Requirements in Healthcare
The 'Black Box' Dilemma: Automated Decision-Making and the Right to Explanation
This section focuses on one of the most debated and legally complex areas of the GDPR's application to AI: the rules governing automated decisions and the transparency obligations that flow from them. This is where the law confronts the opaque nature of advanced AI, creating significant challenges for both compliance and patient autonomy.
3.1. Article 22: Deconstructing the Rules on Solely Automated Decisions
Article 22 of the GDPR is a cornerstone provision designed to protect individuals from the potential risks of automated decision-making. It establishes a default right for a data subject "not to be subject to a decision based solely on automated processing, including profiling, which produces legal effects concerning him or her or similarly significantly affects him or her".
A critical element of this provision is the threshold of being "solely" automated. Many healthcare AI applications are designed as decision-support tools, where the algorithm provides a recommendation, but a human clinician makes the final determination. This introduction of "human intervention" is often intended to take the process outside the strictest scope of Article 22. However, this is not a simple loophole. Regulatory guidance suggests that the human intervention must be "meaningful"; a cursory, rubber-stamping exercise by a clinician who lacks the time, authority, or information to genuinely challenge the AI's output would not suffice to bypass the article's protections. The focus on "solely" automated decisions may, therefore, create a perverse incentive for organizations to implement token human involvement as a form of "ethics washing"—a compliance checkbox rather than a genuine safeguard. Regulators will likely need to develop a robust definition of "meaningful" oversight to prevent this from undermining the purpose of Article 22.
In the healthcare context, a decision that produces "legal or similarly significant effects" is a low bar to clear. An AI-driven diagnosis, a recommended treatment plan, or a risk score that influences access to care would almost certainly meet this threshold. The prohibition in Article 22 is not absolute; it allows for such processing when it is necessary for a contract, authorized by law, or based on the data subject's explicit consent.
3.2. The Contested 'Right to Explanation': Legal Interpretations vs. Technical Reality
While the phrase "right to explanation" does not appear explicitly in the GDPR's articles, it has become a widely discussed concept derived from several provisions. The right is largely inferred from Articles 13, 14, and 15, which require data controllers to provide data subjects with "meaningful information about the logic involved" in automated decision-making, combined with Recital 71, which states that suitable safeguards should include the "right to obtain an explanation of the decision reached".
However, this interpretation is the subject of significant academic and legal debate. Some scholars argue forcefully that a legally enforceable "right to explanation" for a specific automated decision does not actually exist in the GDPR's text, and that the regulation's language is too ambiguous and limited in scope to support such a broad right.
Regardless of this debate, the practical safeguards mandated by the regulation create a de facto need for explanation. When an exception to Article 22 is invoked, the controller must implement measures that allow the individual to "obtain human intervention, to express his or her point of view and to contest the decision". The ability to meaningfully contest a decision is predicated on understanding, at some level, the basis on which it was made. This procedural right to challenge effectively necessitates some form of explanation from the controller. This debate is a proxy for a more fundamental question of due process in the algorithmic age. In traditional legal and ethical systems, a person subject to a significant decision has a right to understand its basis. The "black box" problem threatens this right, as a decision that cannot be understood cannot be meaningfully contested. This suggests that even if a narrow right to explanation does not exist in the current text of the GDPR, there will be immense pressure on courts and future legislators to create equivalent procedural safeguards to uphold these fundamental principles.
3.3. Practical Challenges of Explaining Opaque AI in Clinical Contexts
The legal ideal of transparency collides with the technical reality of many advanced AI systems. The "black box" problem refers to the inherent opacity of models like deep neural networks, whose internal decision-making processes are so complex and high-dimensional that they are not fully comprehensible, even to the experts who designed them.
This opacity creates a critical distinction between "interpretability"—the ability of a trained clinician to understand the reasoning and reliability of an AI's output—and "explainability"—the ability to communicate that logic in a clear and comprehensible manner to a patient. A black box model challenges both. While techniques from the field of Explainable AI (XAI) exist, they often provide only proxies for the model's true logic, such as highlighting which input features were most influential. These explanations can be incomplete, misleading, or not easily interpretable in a clinical context, failing to provide a true causal understanding of the decision.
This leads to a profound clinical and ethical conundrum: If a physician cannot fully understand or articulate the reasoning behind an AI-generated diagnostic or treatment recommendation, how can they fulfill their duty to obtain truly informed consent from the patient?. This dilemma strikes at the heart of the doctor-patient relationship and poses a significant barrier to the responsible deployment of opaque AI in high-stakes medical decisions.
GDPR as a Catalyst for Progress: Fostering Trust and Ethical AI
While the previous sections detailed the significant challenges GDPR poses to AI in healthcare, this section pivots to explore the regulation's positive and transformative impacts. Far from being merely a barrier, the GDPR can be understood as a crucial catalyst for building the trustworthy, ethical, and robust AI systems that are necessary for long-term success and public acceptance in the sensitive domain of healthcare.
4.1. Building the Bedrock of Patient Trust in AI-Driven Healthcare
Widespread adoption of AI in medicine is contingent on patient trust, a currency that is hard-earned and easily lost. Patients and the public harbor legitimate concerns about the privacy of their most sensitive health data and the potential for it to be misused, breached, or used to create discriminatory outcomes.
The GDPR directly addresses these fears by providing a clear, comprehensive, and legally enforceable framework for data protection. Its mandates for transparency, robust security, and individual control (such as the right of access and erasure) can serve to reassure patients that their data is being handled with the utmost care and respect. When patients know their rights are protected by stringent regulations, they are more likely to trust healthcare providers and, by extension, the innovative tools they employ.
In this light, rigorous GDPR compliance ceases to be merely a cost center and becomes a significant competitive advantage. Organizations that can demonstrably prove their commitment to ethical data stewardship are not just avoiding fines; they are building a brand founded on trust. This can lead to greater patient engagement, increased willingness to consent to data use for research, and a stronger, more sustainable market position in an increasingly privacy-conscious world.
4.2. Privacy by Design: Mandating a Proactive Approach to Ethical AI Development
A core tenet of the GDPR, enshrined in Article 25, is the principle of "Privacy by Design" (PbD). This principle mandates that data protection safeguards be embedded into the very architecture of technologies and systems from the earliest stages of development, rather than being bolted on as an afterthought.
This requirement forces a fundamental shift in the AI development lifecycle, moving it from a reactive posture to a proactive one. Under a PbD framework, AI developers must conduct Data Protection Impact Assessments (DPIAs) before beginning a project that is likely to result in a high risk to individuals' rights and freedoms. This process compels them to systematically identify, assess, and mitigate privacy risks before a single line of code is written or a single patient's data is touched.
In practice, implementing PbD for healthcare AI involves several key steps:
Early Collaboration: Involving legal, compliance, and ethics experts alongside data scientists and engineers from a project's inception ensures that regulatory requirements inform the system's design.
Proactive Safeguards: Principles like data minimisation and purpose limitation are considered foundational design constraints, not subsequent compliance checks.
Default Security: Robust technical measures, such as end-to-end encryption and strict, role-based access controls, are implemented as the default setting for the system.
Recent opinions from the European Data Protection Board (EDPB) have reinforced this proactive stance, making it clear that privacy must be "baked in from the start" and that a valid legal basis must be established and documented for both the training and deployment phases of an AI model's lifecycle. This proactive approach, mandated by GDPR, is essential for preventing legal and operational risks down the line.
4.3. Driving a Market for Secure, Accountable, and Robust AI Solutions
The GDPR's stringent requirements are creating a high bar for entry into the EU healthcare market, effectively filtering for AI solutions that are not only innovative but also secure, accountable, and ethically sound. This has a global impact known as the "Brussels Effect," where EU regulations become de facto international standards because multinational companies find it more efficient to engineer their products to the strictest standard and apply it globally.
In this way, GDPR is compelling AI developers worldwide to build better products. The regulation's emphasis on accountability is particularly transformative. The accountability principle requires organizations to not only be compliant but to be able to demonstrate compliance through meticulous documentation, including records of processing activities, DPIAs, and evidence of security measures. This shifts the focus of AI development beyond pure performance metrics like accuracy. It introduces process-oriented metrics such as auditability, transparency, and risk assessment as co-equal markers of a high-quality AI system. This professionalization of applied AI may slow initial development cycles, but it ultimately leads to more robust, reliable, and safer systems, reducing the risk of costly failures and legal challenges post-deployment and fostering a market where ethical innovation is rewarded.
Navigating Compliance: A Toolkit of Privacy-Enhancing Technologies (PETs)
The inherent friction between GDPR's principles and AI's operational needs has catalyzed the development and adoption of a new class of Privacy-Enhancing Technologies (PETs). These innovative approaches offer technical pathways to reconcile the demand for robust data protection with the data-intensive requirements of machine learning. This section provides a practical analysis of the most promising PETs, detailing their mechanisms, benefits, and limitations in the healthcare context.
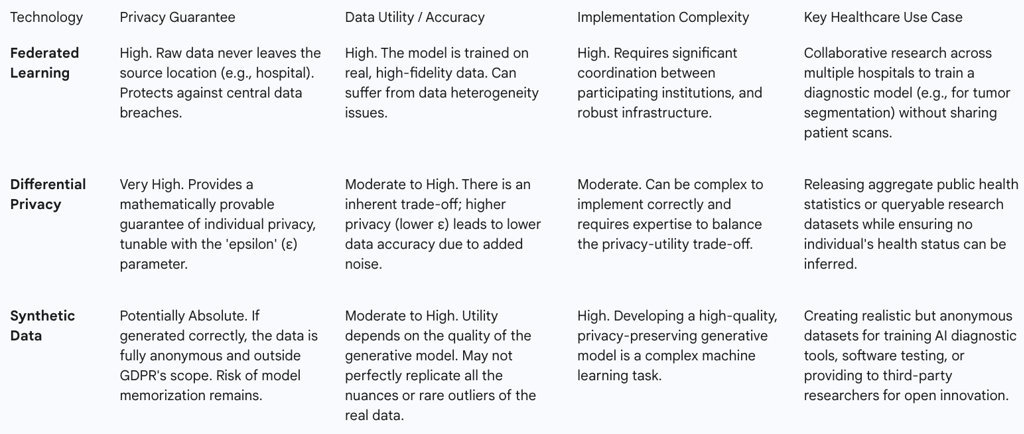
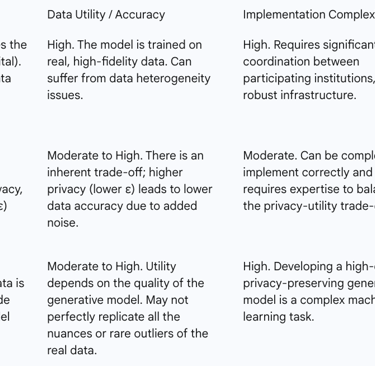
5.1. Federated Learning: Collaborative Training Without Centralised Data
Federated Learning (FL) represents a paradigm shift in how AI models are trained on sensitive data. Instead of the traditional approach of pooling all data into a central server for processing, the FL model is distributed to the data's source, such as individual hospitals or research institutions. The model then trains locally on each institution's private data. Crucially, the raw patient data never leaves the secure perimeter of the hospital. Only the resulting mathematical model updates—anonymized gradients or weights—are sent back to a central aggregator to be combined into an improved global model.
This decentralized architecture directly addresses several core GDPR principles. By keeping data localized, it inherently supports data minimisation and enhances security, dramatically reducing the risk of a catastrophic central data breach. FL enables unprecedented collaboration, allowing multiple institutions to build a more robust and diverse model than any could alone, which is particularly valuable for studying rare diseases. However, FL is not without its challenges. It requires significant technical and organizational coordination and can be vulnerable to sophisticated attacks, such as model inversion, where an adversary might attempt to infer information about the training data from the model updates themselves.
5.2. Differential Privacy: Achieving Anonymity Through Mathematical Rigour
Differential Privacy (DP) offers a formal, mathematical guarantee of privacy. It works by injecting a precisely calibrated amount of statistical "noise" into a dataset or, more commonly, into the results of queries performed on that dataset. The noise is carefully calculated to be large enough to obscure the contribution of any single individual, ensuring that the output of an analysis would be nearly identical whether or not that person's data was included. This provides plausible deniability for every participant in the dataset.
From a GDPR perspective, DP is a powerful tool because it provides a strong, provable method of anonymization that can help organizations meet the high standard required to take data outside the scope of the regulation. It is a prime example of "data protection by design". The primary challenge with DP lies in the inherent trade-off between privacy and utility. A stronger privacy guarantee (achieved by adding more noise) inevitably reduces the accuracy and utility of the data. Finding the appropriate balance, or "privacy budget," is a critical and context-dependent task, especially in medical applications where diagnostic accuracy is paramount.
5.3. Synthetic Data Generation: Innovation Without Real Patient Exposure
Synthetic data generation involves training a machine learning model, often a Generative Adversarial Network (GAN), on a real-world dataset. This trained model then generates an entirely new, artificial dataset that mimics the statistical patterns, distributions, and correlations of the original data but contains no actual patient records.
If generated with sufficient rigor to prevent the "memorization" or leakage of real patient information, synthetic data can be considered truly anonymous and therefore fall outside the scope of the GDPR. This unlocks immense potential, allowing organizations to freely share data for open research, train AI models without privacy constraints, and test software without exposing protected health information. However, significant risks remain. If the generative model is poorly designed or overfits the training data, the synthetic output can inadvertently replicate real patient data or allow for re-identification, creating a false sense of security and leading to serious GDPR violations.
The implementation of these technologies reveals that PETs are not a simple "fix" for GDPR compliance. Instead, they are sophisticated risk mitigation tools that shift the compliance burden. The focus moves from traditional data governance (e.g., securing a central database) to the much more complex domain of model governance. An organization must now be able to prove that its federated learning updates do not leak information, that its choice of a differential privacy budget is legally justifiable, or that its synthetic data is statistically robust against re-identification. This requires a new, hybrid expertise at the intersection of data science, cybersecurity, and data protection law.
Table 3: Analysis of Privacy-Enhancing Technologies (PETs)
The Innovation Debate: Real-World Impacts and Case Studies
This section directly confronts the central question of whether the GDPR is ultimately a help or a hindrance to medical progress. It moves from principles and technologies to examine the real-world evidence and arguments that define this critical debate.
6.1. The Argument for Stifled Innovation: GDPR as a Competitive Disadvantage
A prominent viewpoint holds that the GDPR, despite its laudable goals, places European organizations at a significant competitive disadvantage in the global AI race. The argument posits that the regulation's stringent requirements and legal ambiguities create an environment that is hostile to the kind of rapid, data-driven experimentation that fuels AI innovation in regions like the United States and China.
Specific hindrances frequently cited include:
Increased Costs and Complexity: Achieving and maintaining GDPR compliance demands substantial investment in legal counsel, Data Protection Officers, and specialized technologies. These resources are thereby diverted from core research and development activities.
Barriers to Data Access: The strict interpretation of purpose limitation and the immense practical difficulty of obtaining explicit consent for large-scale research on historical datasets severely restrict the pool of data available for training and validating new AI models.
Chilling Effect of Fines: The threat of draconian fines—up to 4% of annual global turnover—fosters a deeply risk-averse culture. This discourages organizations, particularly small and medium-sized enterprises, from exploring novel uses of data that might fall into a legal gray area.
Delayed Market Entry: The cumulative burden of compliance can slow down development cycles, meaning European startups may reach the market with their innovations later than their international competitors who face fewer data-related hurdles in their initial phases.
However, this "stifled innovation" argument can be reframed. The evidence suggests that GDPR does not create a fundamental inability to innovate so much as it increases the cost and complexity of doing so. The regulation has not blocked AI development but has instead re-routed it. The direct path of using raw data with minimal constraints is closed, but a new path—one that runs through the landscape of Privacy-Enhancing Technologies—has opened. The debate, therefore, is not a binary choice between innovation and privacy, but rather a societal judgment on whether the benefits of privacy-preserving innovation are worth the increased upfront investment and potential slowdown in development speed.
6.2. Case Study Analysis: The DeepMind/NHS Royal Free Controversy and its Lessons
The 2016 partnership between the UK's Royal Free NHS Trust and Google's DeepMind provides a seminal case study on the intersection of healthcare AI and data protection. The project involved the transfer of 1.6 million patient records to DeepMind to test an app designed for the early detection of acute kidney injury.
The project generated significant public and regulatory backlash. In 2017, the UK's Information Commissioner's Office (ICO) ruled that the Trust had breached data protection law (the pre-GDPR Data Protection Act 1998) by failing to adequately inform patients that their data would be used for this purpose. The ICO's landmark ruling stated that patients would not have "reasonably expected" their data to be shared with a commercial entity for technology testing and famously concluded, "the price of innovation does not need to be the erosion of fundamental privacy rights."
This case is a powerful illustration of the principles that the GDPR would later codify and strengthen. It underscores the critical importance of transparency and having a lawful basis for processing that aligns with the original purpose of data collection. The controversy reveals that the greatest risk to healthcare AI projects may not be technical failure but a failure of governance that leads to a loss of public trust and social license. The project was technologically promising but was ultimately derailed by its failure to meet fundamental data protection expectations. In this light, GDPR's principles are not merely legal hurdles; they are a codified framework for maintaining the social license necessary for any AI initiative in healthcare to succeed.
6.3. Evaluating the True Impact on Medical Research and Clinical Trials
The application of GDPR to medical research and clinical trials is a particularly complex and contested area. Some in the research community argue that the regulation's fragmented implementation across member states and its strict rules on secondary data use have created significant barriers, impeding the progress of science and making multi-regional clinical trials more difficult to conduct. Repurposing data collected during a clinical trial to train a new AI model, for example, now requires a rigorous compatibility assessment to ensure it does not violate the purpose limitation principle.
However, this perspective is not universal. The GDPR itself contains a broad and favorable regime for "scientific research," which establishes a presumption that further processing for research purposes is compatible with the initial purpose of collection, provided that appropriate safeguards are implemented. These safeguards often involve the privacy-enhancing techniques discussed in the previous section.
As AI becomes more integrated into clinical trials—for optimizing patient recruitment, analyzing trial data, and monitoring participants—GDPR compliance is a central consideration. The regulation does not prohibit these innovative applications but rather demands that they be designed and executed with privacy and data protection as core components. While this adds layers of complexity and cost, it also forces a more rigorous, secure, and ethically sound approach to research, which can enhance the quality and trustworthiness of the results.
The Future Horizon: The EU AI Act and the Evolving Regulatory Ecosystem
The GDPR does not operate in a vacuum. The regulatory landscape for AI in Europe is rapidly evolving, with the landmark EU AI Act set to create a new, comprehensive governance framework. This final analytical section looks to the future, examining how the AI Act will interact with the GDPR to forge a multi-layered regulatory ecosystem for AI in healthcare.
7.1. Introducing the EU AI Act: A Risk-Based Approach to Regulation
The EU AI Act is the world's first horizontal, comprehensive legislation specifically targeting artificial intelligence. Its core innovation is a risk-based approach that categorizes AI systems into four tiers, imposing regulatory obligations commensurate with the level of potential harm :
Unacceptable Risk: AI practices that are considered a clear threat to safety, livelihoods, and rights are banned outright (e.g., social scoring by governments).
High Risk: This is the most critical category for the healthcare sector. It includes AI systems that are themselves medical devices or that function as safety components of regulated products. These systems are subject to a stringent set of obligations before they can be placed on the market.
Limited Risk: AI systems that require specific transparency obligations, such as chatbots, which must disclose that users are interacting with a machine.
Minimal Risk: The vast majority of AI systems, such as AI-enabled video games or spam filters, which are largely unregulated.
For high-risk AI systems, the Act mandates a suite of requirements, including the implementation of robust risk assessment and mitigation systems, high standards of data governance to prevent discriminatory outcomes, detailed technical documentation, logging of activity to ensure traceability, clear information for users, and appropriate human oversight.
7.2. Interplay and Overlap: How the AI Act Complements and Complicates GDPR for Medical AI
The AI Act is designed to be complementary to the GDPR, not to supersede it. The two regulations govern different, albeit overlapping, aspects of AI. The GDPR regulates the lawful processing of
personal data that might be used by an AI system. The AI Act, in contrast, regulates the AI system itself as a product or service, focusing on its safety, performance, and impact on fundamental rights.
The AI Act's requirements for high-quality, representative training data and the mitigation of bias directly reinforce the GDPR's principles of fairness and accuracy. In essence, the AI Act adds a product safety and fundamental rights layer on top of the GDPR's data protection foundation. For developers of AI-powered medical devices, this creates a complex, tripartite compliance challenge: they must simultaneously adhere to the Medical Device Regulation (MDR), the GDPR, and the AI Act.
This convergence creates a tightly interconnected compliance ecosystem with cascading risks. A critical provision in the AI Act requires that the formal Declaration of Conformity for a high-risk AI medical device explicitly states that the system is compliant with the GDPR. This creates a direct and powerful link between the two laws. A finding of a serious GDPR violation related to the data used to train an AI medical device could potentially invalidate that device's regulatory approval under the AI Act. This means that a failure in data protection can cause the entire product's legal standing to collapse. Organizations cannot, therefore, treat these regulations in silos; they require a holistic governance strategy that addresses product safety (MDR), data privacy (GDPR), and algorithmic integrity (AI Act) as an integrated whole.
7.3. Expert Perspectives on the Future of AI Governance in European Healthcare
The creation of this comprehensive regulatory framework has been met with a mix of apprehension and optimism from industry experts. Some express concern that the cumulative regulatory burden of the MDR, GDPR, and AI Act will stifle innovation, increase costs, and delay the market entry of European startups compared to their less-regulated international counterparts.
Others, however, view this as a strategic opportunity for Europe to establish itself as the global leader in "Trustworthy AI". By creating a clear, albeit demanding, legal framework, the EU can build the patient and clinician confidence necessary for widespread adoption. The hope is that the AI Act, like the GDPR before it, will have a global "Brussels Effect," compelling international companies to adopt its high standards as a global benchmark.
A key enabler of this future vision will be the European Health Data Space (EHDS), an ambitious initiative designed to create a unified framework for the secure access and exchange of health data for research, innovation, and policymaking. If successful, the EHDS could provide the high-quality, privacy-compliant data necessary to train the next generation of medical AI, helping to resolve some of the data access challenges created by the GDPR. Furthermore, the AI Act's mandate for "appropriate human oversight" will force a fundamental re-evaluation of clinical workflows and professional liability. This is not merely a technical feature to be added to a device; it is a socio-technical challenge that will require redesigning clinical pathways, clarifying liability frameworks, and investing heavily in training the healthcare workforce to work effectively and safely alongside AI systems.
Conclusion and Strategic Recommendations
The integration of Artificial Intelligence into healthcare, governed by the stringent principles of the GDPR and the emerging framework of the EU AI Act, stands at a critical juncture. The relationship is one of profound tension but also immense potential. While GDPR's principles of data minimisation, purpose limitation, and explicit consent create significant hurdles for data-intensive AI development, they also serve as a powerful catalyst for innovation in privacy-preserving technologies and act as the essential bedrock for building patient trust. The regulation is not merely a barrier to progress but a crucible, forcing the development of AI that is not only powerful but also private, fair, and accountable. Navigating this complex landscape requires a strategic, proactive, and collaborative approach from all stakeholders.
8.1. For Policymakers and Regulators
Harmonize Interpretation and Guidance: European and national data protection authorities should collaborate to issue clear, practical, and harmonized guidance on the application of GDPR to AI. Priority areas should include clarifying the scope of the scientific research exemption, providing a robust definition of "meaningful" human intervention under Article 22, and establishing clear standards for what constitutes legally sufficient anonymization for synthetic and differentially private data.
Invest in and Promote Regulatory Sandboxes: Actively fund and promote the use of regulatory sandboxes, as envisioned in the AI Act. These controlled environments are crucial for enabling startups and researchers to test innovative healthcare AI solutions in a real-world setting while working collaboratively with regulators to ensure compliance, thereby lowering the barrier to entry for responsible innovation.
Develop Clear Liability Frameworks: Proactively address the "many hands" problem of AI-related harm by developing clear legal frameworks for liability and accountability. This will provide legal certainty for healthcare providers and developers, ensuring that responsibility can be fairly assigned in the event of an error without creating a climate of fear that stifles the adoption of beneficial technologies.
8.2. For Healthcare Organisations and Providers
Establish a Holistic AI Governance Strategy: Move beyond siloed compliance efforts. Create a cross-functional AI governance committee that includes legal counsel, data protection officers, clinicians, IT specialists, and ethicists. This body should be responsible for developing a unified strategy that addresses the interconnected requirements of the GDPR, the AI Act, and the MDR simultaneously.
Prioritize AI Literacy and Education: Invest in comprehensive training programs for both clinicians and administrative staff. Clinicians must be equipped with the skills to understand the capabilities and limitations of AI tools to provide meaningful oversight. All staff must understand their data protection responsibilities. Furthermore, develop clear, transparent communication materials for patients to explain how and why their data is being used in AI systems, fostering trust and enabling truly informed consent.
Conduct Rigorous Due Diligence on AI Vendors: When procuring third-party AI systems, evaluation must go beyond clinical efficacy and cost. Demand comprehensive documentation from vendors detailing their data governance practices, bias detection and mitigation strategies, security measures, and evidence of GDPR and AI Act compliance. Make "compliance by design" a key procurement criterion.
8.3. For AI Developers and Technology Companies
Embed Privacy by Design as a Core Philosophy: Treat data protection and ethical considerations as foundational elements of product design, not as a final compliance check. Integrate privacy engineers and legal experts into development teams from the project's inception. Conduct DPIAs as a standard, proactive part of the development lifecycle.
Innovate in Transparency and Privacy as a Competitive Differentiator: Invest heavily in the development and implementation of PETs and Explainable AI (XAI). Market your products not only on their accuracy but on their trustworthiness, security, and transparency. In the European healthcare market, provable privacy is a key product feature, not just a legal obligation.
Maintain Meticulous and Demonstrable Accountability: The ability to demonstrate compliance is as important as being compliant. Maintain immaculate records of data sources, processing activities, consent mechanisms, training methodologies, risk assessments, and bias-auditing procedures. This documentation is essential for satisfying the accountability principle of the GDPR and the technical documentation requirements of the AI Act.