Ensuring GDPR Compliance for AI Solutions
Integrating robust data security measures throughout the AI development lifecycle is crucial for ensuring the privacy, integrity, and trustworthiness of AI systems. Here are some best practices for integrating data security into AI development.


The General Data Protection Regulation (GDPR) establishes a comprehensive framework for the protection of personal data, built upon seven core principles articulated in Article 5. While these principles were conceived in a pre-AI-dominant era, their application to modern artificial intelligence (AI) systems is not merely a matter of direct translation but one of complex interpretation and adaptation. The scale, autonomy, and inherent opacity of AI technologies create profound tensions with these foundational tenets, demanding a more nuanced and technically informed approach to compliance. Organizations that develop or deploy AI solutions must move beyond a surface-level understanding of these principles and engage deeply with the unique challenges AI presents to each one.
1.1 Lawfulness, Fairness, and Transparency
This triad of principles forms the bedrock of the GDPR, mandating that all processing of personal data must be lawful, fair, and transparent in relation to the data subject. While interconnected, each principle faces distinct and significant challenges when confronted with the realities of AI development and deployment.
Lawfulness
Under the GDPR, all processing of personal data must rest on one of the six legal bases outlined in Article 6: consent, contract, legal obligation, vital interests, public task, or legitimate interests. For AI systems, particularly during the data-intensive training phase, establishing a valid lawful basis is a primary and often formidable hurdle.
The sheer volume of data required to train robust machine learning models makes obtaining valid, specific, and informed consent from every individual impractical, if not impossible. Furthermore, consent may be deemed invalid if there is a significant power imbalance between the controller and the data subject (e.g., in an employment context) or if the purposes of processing are not sufficiently specified at the time of collection—a common issue with exploratory AI models.
Consequently, many organizations turn to legitimate interest as the legal basis for training AI models. However, this is not a straightforward alternative. Relying on legitimate interest necessitates a rigorous three-part test: identifying a legitimate interest, demonstrating the processing is necessary to achieve it, and conducting a comprehensive balancing test to ensure that the interest is not overridden by the rights and freedoms of the data subjects. For complex and potentially high-risk AI processing, this balancing act is exceptionally delicate and is frequently challenged by data protection authorities. The potential for AI to generate unexpected insights or have significant impacts on individuals raises the bar for what constitutes a defensible legitimate interest.
Fairness
The principle of fairness requires that personal data is handled in ways that people would reasonably expect and not used in a manner that has an unjustified adverse effect on them. In the context of AI, this principle has undergone a critical evolution. The focus has shifted from a purely procedural check—such as providing a clear privacy notice—to a substantive, outcome-oriented obligation that demands the active prevention of discriminatory effects.
This shift is a direct response to one of the most significant risks posed by AI: the potential to inherit, amplify, and systematize biases present in historical training data. An AI model trained on biased data will inevitably produce biased outputs, leading to discriminatory outcomes in areas such as recruitment, credit scoring, or law enforcement. Regulatory bodies, such as the UK's Information Commissioner's Office (ICO), have explicitly stated that any processing of personal data using AI that leads to unjust discrimination violates the fairness principle.
This establishes a clear causal chain: biased data leads to a discriminatory AI model, which in turn results in a breach of a core GDPR principle. This transformation of "fairness" into a substantive obligation has profound implications. It moves the compliance burden from the legal department to a cross-functional team involving data scientists, ethicists, and compliance officers. Organizations are now required not just to be transparent about potential risks but to actively audit their datasets for bias, measure the fairness of their models' outputs using statistical techniques, and implement technical mitigation strategies. The EU AI Act further codifies this by mandating the examination of datasets for possible biases as a prerequisite for high-risk AI systems.
Transparency
Transparency is a cornerstone of the GDPR, requiring controllers to provide individuals with clear, concise, and easily accessible information about the processing of their personal data. This obligation is fundamentally challenged by the inherent complexity and opacity of many advanced AI models, particularly "black box" systems like deep neural networks. In these models, the relationship between inputs and outputs can be so complex that even the developers who created them cannot fully explain the reasoning behind a specific decision.
This opacity is in direct conflict with the GDPR's requirement, particularly in the context of automated decision-making under Article 22, to provide "meaningful information about the logic involved". Simply stating that a decision was "made by an algorithm" is insufficient. Fulfilling this transparency mandate requires a concerted effort to develop and deploy methods of "Explainable AI" (XAI), which can translate complex model behavior into human-comprehensible terms. The technical difficulty of achieving true explainability, balanced against the need to protect intellectual property and trade secrets, represents one of the most significant compliance tensions at the intersection of AI and data protection law.
1.2 Purpose Limitation
The principle of purpose limitation, enshrined in Article 5(1)(b), dictates that personal data must be "collected for specified, explicit and legitimate purposes and not further processed in a manner that is incompatible with those purposes". This principle imposes a static, upfront constraint on data processing, a constraint that is fundamentally at odds with the dynamic and exploratory nature of many AI applications.
The core value proposition of advanced AI and machine learning is often its ability to analyze vast datasets to discover novel, previously unknown patterns, correlations, and potential applications. This is an adaptive, ongoing process of discovery. The GDPR, however, demands that the purpose of processing be clearly defined before the processing begins. This creates a direct and unavoidable friction.
When an AI system, through its learning process, uncovers a valuable but entirely new and unforeseen use for the data it is processing, this constitutes "further processing" under the GDPR. If this new purpose is not compatible with the original, narrowly defined purpose communicated to the data subject, it is unlawful without a new legal basis, which typically means obtaining fresh consent. This leads to a high risk of "function creep" or "purpose creep," where data legitimately collected for one reason is repurposed for another without a compliant legal pathway.
This conflict forces organizations into a difficult strategic dilemma. On one hand, they could define the initial purpose for AI processing so broadly as to encompass any potential future discoveries. However, such a vague and non-specific purpose would likely fail to meet the "specified" and "explicit" requirements of the GDPR. On the other hand, they could adhere to a very narrow and specific purpose, but this would severely hamstring the AI's exploratory capabilities, potentially negating a significant portion of its intended business value and return on investment. The purpose limitation principle, therefore, acts as a direct governor on the scope and pace of AI innovation within a compliance-conscious organization, demanding a careful and deliberate approach to defining and documenting the objectives of any AI project from its inception.
1.3 Data Minimisation
Article 5(1)(c) of the GDPR establishes the principle of data minimisation, requiring that personal data be "adequate, relevant and limited to what is necessary in relation to the purposes for which they are processed". This principle explicitly prohibits the speculative collection of data on a "just in case" basis.
This tenet directly clashes with the prevailing paradigm in machine learning, where model performance and accuracy often correlate positively with the volume and variety of the training data. The "more data is better" approach, common in AI development, creates a significant compliance challenge. Justifying the "necessity" of every individual data field within a training dataset containing millions or even billions of records is a substantial, and often impractical, burden.
To reconcile this tension, organizations must shift their strategic focus. Rather than attempting to justify the necessity of massive data volumes—a difficult legal argument—the emphasis should be on minimizing the risk associated with that data. This is achieved through the proactive implementation of Privacy-Enhancing Technologies (PETs). These technologies allow for the extraction of statistical value from data while reducing its identifiability and privacy impact. Key PETs relevant to AI include:
Anonymization and Pseudonymization: These are foundational techniques. Anonymization aims to permanently prevent identification, while pseudonymization replaces direct identifiers with artificial ones, allowing for re-identification only with a separate key. These are explicitly mentioned in the GDPR as appropriate safeguards.
Federated Learning: This decentralized approach allows an AI model to be trained on local data across multiple devices or servers without the raw data ever being centralized. Only the aggregated, anonymized model updates are shared, significantly reducing data transfer and exposure risks.
Synthetic Data: This involves creating an artificial dataset that mimics the statistical properties of a real dataset without containing any actual personal information. It can be used to train and test models in a privacy-safe environment.
By embedding these technologies into the AI lifecycle, organizations can align with the spirit of data minimisation by reducing privacy risks, even when the volume of processed information remains large.
1.4 Accuracy
The accuracy principle, under Article 5(1)(d), mandates that personal data must be accurate and, where necessary, kept up to date. Controllers must take "every reasonable step" to ensure that inaccurate personal data is erased or rectified without delay.
In the AI context, the concept of "accuracy" becomes twofold. It applies not only to the accuracy of the input data used to train and operate the system but also to the statistical accuracy of the model's output, which could be a prediction, a classification, a recommendation, or generated content. While the quality of input data directly influences the quality of the output ("garbage in, garbage out"), the accuracy of the output itself presents a novel set of GDPR challenges.
A particularly acute problem arises with generative AI models, which are prone to "hallucinations"—the generation of outputs that are plausible and confidently stated but are factually incorrect. When these hallucinations involve personal data, they create inaccurate information about an individual. For example, a generative AI might incorrectly state that a named individual was convicted of a crime or holds a particular professional qualification. This is a direct breach of the accuracy principle.
This issue is compounded by the technical difficulty of fulfilling the data subject's right to rectification (Article 16) in such cases. Correcting a hallucinated "fact" about an individual is not as simple as editing a database entry. The inaccuracy stems from the complex, learned patterns within the model itself. Rectifying it may require complex interventions, such as fine-tuning the model with corrected data or, in extreme cases, retraining it, which can be technically complex and costly. Organizations deploying generative AI must therefore develop processes not only to identify such inaccuracies but also to respond effectively to rectification requests, a challenge that is still an active area of technical research.
1.5 Storage Limitation
The principle of storage limitation, found in Article 5(1)(e), requires that personal data be kept "in a form which permits identification of data subjects for no longer than is necessary for the purposes for which the personal data are processed". This means organizations must not hold onto personal data indefinitely. They are expected to establish and enforce clear data retention periods, after which the data should be securely deleted or anonymized.
This principle poses a significant operational challenge for AI development. The large datasets used for training, validating, and testing AI models are valuable assets. Organizations often have a strong incentive to retain these datasets for long periods, or even indefinitely, for several reasons:
Model Retraining: To update models or correct for "model drift" over time.
New Model Development: To use the existing data to train new, different models in the future.
Auditing and Explainability: To be able to trace a model's decision back to the data it was trained on.
This desire for long-term data retention is in direct conflict with the storage limitation principle. To comply, organizations must move away from a default "keep everything" approach. A robust data governance framework is required, which includes a specific data retention policy for AI-related datasets. This policy should define clear time limits for the retention of training data in an identifiable form. Once a model is successfully trained and deployed, the underlying training data should, as a default, be either securely deleted or irreversibly anonymized, unless a specific, documented, and time-bound purpose for its continued retention can be justified under the GDPR.
1.6 Integrity and Confidentiality (Security)
Article 5(1)(f) mandates that personal data be processed in a manner that ensures its security and confidentiality. This includes protection against "unauthorised or unlawful processing and against accidental loss, destruction or damage," using appropriate technical and organizational measures (TOMs). Standard security measures like encryption, access controls, and regular security audits are baseline requirements.
However, AI systems introduce a new class of security vulnerabilities that go beyond traditional cybersecurity threats. A GDPR-compliant security posture for AI must specifically address these novel attack vectors :
Model Inversion Attacks: These attacks attempt to reverse-engineer the model to reconstruct sensitive information from the training data. For example, an attacker could query a facial recognition model to reconstruct images of the faces it was trained on.
Membership Inference Attacks: These attacks aim to determine whether a specific individual's data was part of the model's training set. This can reveal sensitive information, such as an individual's participation in a medical study.
Data Poisoning: This involves an attacker deliberately feeding malicious or corrupted data into the training set to manipulate the model's behavior. This could be used, for example, to cause a loan approval model to systematically reject certain types of applicants or to create backdoors in a security system.
Evasion Attacks: These involve crafting specific inputs during the deployment phase (inference time) that are designed to be misclassified by the model, for example, to bypass a spam filter or malware detection system.
Protecting against these sophisticated threats requires a security framework that is integrated throughout the entire AI lifecycle, from securing the data pipeline and training environments to hardening the deployed model and continuously monitoring its operations.
1.7 Accountability
Accountability is the lynchpin principle of the GDPR, as stated in Article 5(2). It holds that the data controller is not only responsible for complying with the other six principles but "must be able to demonstrate" that compliance. This requires a proactive and documented approach to data protection governance.
For AI systems, the accountability burden is significantly heightened due to their complexity, autonomy, and potential for high-impact, opaque decision-making. Simply asserting compliance is insufficient; organizations must create a comprehensive and auditable trail of evidence that substantiates their claims. Demonstrating accountability for an AI system is a profound challenge that necessitates a robust, dedicated AI Governance framework.
This framework must generate and maintain meticulous documentation covering the entire AI lifecycle. Key artifacts for demonstrating accountability include:
Data Protection Impact Assessments (DPIAs): The complete DPIA report, detailing identified risks and mitigation measures.
Lawful Basis Justification: Clear documentation of the chosen lawful basis for processing, including the full legitimate interests assessment if applicable.
Data Provenance Records: Records detailing the source, lineage, and pre-processing steps for all training, validation, and testing data.
Model Documentation ("Model Cards"): Detailed descriptions of the AI model's architecture, intended use, performance metrics, and limitations.
Bias and Fairness Audits: The results of statistical tests and audits conducted to detect and mitigate bias in the data and model.
Validation and Testing Reports: Evidence of the model's accuracy, robustness, and performance against defined benchmarks.
Records of Human Oversight: Logs of decisions reviewed by human operators, including instances where the AI's recommendation was challenged or overturned.
Both the GDPR and the EU AI Act place a heavy emphasis on this demonstrable accountability, making it a central pillar of any compliant AI strategy.
Navigating the AI Development Lifecycle with Data Protection by Design
The GDPR mandates the principles of "Data Protection by Design" and "Data Protection by Default" under Article 25. This is not an optional best practice but a core legal requirement. "By Design" means that data protection must be integrated into the architecture of systems and processes from the very earliest stages of development, not added as an afterthought. "By Default" requires that the most privacy-protective settings are applied automatically, without any user intervention. Applying this framework systematically across the four distinct phases of the AI development lifecycle—planning, data preparation, model development, and deployment—is essential for building compliant and trustworthy AI solutions.
2.1 Phase 1: Planning and Design - The Primacy of the DPIA
The planning and design phase is the most critical juncture for embedding data protection. Decisions made here have cascading effects throughout the entire lifecycle. The central compliance activity in this phase is the Data Protection Impact Assessment (DPIA).
Under Article 35 of the GDPR, a DPIA is mandatory for any processing that is "likely to result in a high risk to the rights and freedoms of natural persons". Given their nature, AI systems almost invariably trigger this requirement, especially when they involve:
Systematic and extensive evaluation or profiling (e.g., credit scoring, employee performance monitoring).
Large-scale processing of special categories of data (e.g., health data, biometric data).
The use of innovative technology.
A DPIA for an AI system must be exceptionally rigorous and go beyond a standard risk assessment. It is a systematic process that must, at a minimum, contain :
A Systematic Description of the Processing: This includes detailing the nature, scope, context, and purposes of the AI system. It should map the entire data flow, from data sources and collection methods to storage, usage, sharing, and deletion protocols.
An Assessment of Necessity and Proportionality: This step requires a clear justification for why the AI system is needed to achieve the stated purpose and an evaluation of whether the processing is proportionate to that goal. It should consider if less intrusive means could achieve the same outcome.
An Assessment of Risks to Rights and Freedoms: This is the core of the DPIA. For AI, the risks extend far beyond data breaches. The assessment must identify and evaluate the likelihood and severity of risks such as algorithmic discrimination, financial loss, reputational damage, loss of individual autonomy due to automated decisions, and chilling effects from monitoring.
The Measures Envisaged to Address the Risks: The DPIA must conclude by detailing the specific technical and organizational measures that will be implemented to mitigate the identified risks. This could include using PETs, implementing bias detection tools, establishing robust human oversight procedures, and defining clear governance policies.
Regulatory bodies like the ICO provide detailed guidance and toolkits to help organizations structure their DPIAs, with a strong emphasis on considering fairness, potential for bias, and the statistical accuracy of the AI model from the very beginning of the project. The DPIA is not a one-time, check-box exercise; it is a living document that should be reviewed and updated as the AI system evolves.
2.2 Phase 2: Data Collection and Pre-processing - Lawful Basis and Data Quality
Once the project is deemed viable through the DPIA, the focus shifts to the data that will fuel the AI system. This phase is governed by two critical compliance imperatives: establishing a lawful basis and ensuring data quality.
The lawful basis for processing the vast datasets needed for training must be formally established and documented during this phase. As previously discussed, this is a complex legal determination with significant downstream consequences. For example, the right to data portability under Article 20 only applies when the processing is based on consent or the performance of a contract, so the choice of lawful basis directly impacts which rights data subjects can exercise.
Beyond the legal basis, this phase must be governed by a robust data governance framework that prioritizes data quality. The adage "garbage in, garbage out" is acutely true for AI; the performance, accuracy, and fairness of the final model are entirely dependent on the quality of the data it is trained on. Key data governance activities in this phase include:
Assessing Relevance and Adequacy: Ensuring the data collected is directly relevant to the model's purpose and sufficient for training without being excessive, in line with the data minimisation principle.
Ensuring Accuracy: Implementing procedures to verify the accuracy of the data and correct or remove errors.
Checking for Representativeness: This is the most critical step for fairness. The dataset must be carefully analyzed to ensure it is representative of the population the AI will affect. It must be checked for historical biases and under-representation of demographic groups. Failure to do so is a primary cause of discriminatory AI systems. This proactive examination for bias is a core requirement under the EU AI Act for high-risk systems, making it a point of convergence between the two regulatory frameworks.
2.3 Phase 3: Model Training and Validation - Upholding Rights in Opaque Systems
During the model training phase, the prepared data is used to teach the algorithm to recognize patterns and make predictions. From a GDPR perspective, this phase introduces a significant challenge that can be termed "compliance debt."
Once personal data is processed and its patterns are embedded into the internal logic of a trained model (e.g., the weights of a neural network), it becomes intrinsically linked to the model's functionality. At this point, responding to data subject rights requests for that data becomes technically difficult and expensive. For instance, fulfilling a request for erasure (Article 17) or rectification (Article 16) for a piece of data that influenced the model's training may require the entire model to be retrained from scratch with the corrected or removed data. This is a costly and time-consuming process.
To manage this compliance debt, organizations must anticipate these requests from the design phase. Where feasible, systems should be architected to facilitate the removal or amendment of individual data points' influence without necessitating a complete rebuild.
Accountability remains paramount during this phase. Meticulous records of the training process must be maintained. This documentation is a cornerstone of the accountability principle and a specific requirement for high-risk systems under the EU AI Act. It should include :
The exact versions of the datasets used for training, validation, and testing.
The model's architecture, parameters, and hyperparameters.
The results of all validation and testing, including performance metrics for accuracy, robustness, and fairness across different demographic subgroups.
2.4 Phase 4: Deployment and Monitoring - Transparency and Human Oversight
The deployment of the AI system marks its transition from a development project to an operational process that interacts with and affects individuals. At this stage, compliance obligations related to transparency and ongoing oversight come to the forefront.
When the system is live, transparency obligations are triggered at the point of interaction. Users must be clearly and proactively informed that they are interacting with an AI system, a specific requirement for technologies like chatbots under the EU AI Act. For systems making or supporting decisions that fall under Article 22, the more detailed transparency requirements to provide meaningful information about the logic involved are activated. This information must be provided in clear, plain language within privacy notices or just-in-time notifications.
Compliance is not a static achievement; it is a continuous process. An AI model is not a fixed asset. Its performance can degrade over time as the real-world data it encounters diverges from its training data—a phenomenon known as "model drift." Furthermore, new biases or security vulnerabilities can emerge as the system operates in a dynamic environment.
Therefore, organizations must implement a program of continuous monitoring for all deployed AI systems. This program should track key performance indicators related to:
Model Accuracy: To detect model drift and ensure continued effectiveness.
Fairness Metrics: To monitor for any emergent biases or discriminatory outcomes across different population groups.
Security: To detect potential attacks or anomalous behavior.
Usage and Oversight: To log how the system is being used and how human overseers are interacting with it.
Regular, periodic audits of the AI system are a critical component of this monitoring process and are essential for demonstrating ongoing accountability to regulators.
Automated Decision-Making and Data Subject Rights (Article 22)
Article 22 of the GDPR is one of the most debated and critical provisions for the governance of AI. It establishes specific rights for individuals in relation to decisions made about them without human involvement. For many of the most impactful AI applications—in finance, recruitment, healthcare, and justice—a thorough understanding and careful application of Article 22 is a non-negotiable aspect of compliance.
3.1 Scope of Article 22: A High Threshold
Article 22(1) grants a data subject the right "not to be subject to a decision based solely on automated processing, including profiling, which produces legal effects concerning him or her or similarly significantly affects him or her". This right is not absolute and is subject to a strict, two-pronged test for applicability.
First, the decision must be based "solely on automated processing." This means there is no meaningful human involvement in the decision-making process itself. The critical term here is "meaningful." If a human operator merely reviews an AI's output and passively accepts it without genuine assessment or the authority to override it, the decision is still considered "solely automated." This practice, often referred to as "rubber-stamping," does not introduce the level of human agency required to take the process outside the scope of Article 22.
Second, the decision must produce "legal or similarly significant effects."
Legal Effects: These are decisions that impact an individual's legal rights or status. Examples include decisions about entitlement to social security benefits, the cancellation of a contract, or eligibility to vote.
Similarly Significant Effects: This category is broader and covers decisions that have a comparably serious impact on an individual's circumstances, behavior, or choices. Regulatory guidance and case law have established that this includes decisions such as the automatic refusal of an online credit application, automated e-recruiting tools that filter out candidates without human review, or algorithmic decisions on university admissions.
If a decision-making process meets both of these criteria, it is generally prohibited. However, Article 22(2) provides three exceptions where such processing is permitted :
The decision is necessary for entering into, or performance of, a contract between the data subject and the controller.
The decision is authorised by Union or Member State law to which the controller is subject.
The decision is based on the data subject's explicit consent.
It is crucial to note that even when one of these exceptions applies, the controller is still obligated to implement specific safeguards to protect the individual's rights, as detailed in Article 22(3).
3.2 The Imperative of Meaningful Human Intervention
The concept of "meaningful human intervention" is central to the interpretation of Article 22. It is the dividing line between a decision that is "solely automated" and one that is merely "AI-assisted." To be considered meaningful, human involvement must be substantive. Regulatory guidance from bodies like the ICO and the European Data Protection Board clarifies that the human reviewer must have :
Authority: The genuine power to override the automated decision.
Competence: The necessary training and expertise to understand the AI system's output and its limitations.
Ability: The capacity to conduct a thorough assessment of all relevant data, including any additional information the data subject may provide, rather than just reviewing the AI's recommendation in isolation.
A significant risk in designing human-in-the-loop systems is automation bias. This is a well-documented cognitive tendency for humans to over-rely on the outputs of automated systems, ceasing to apply their own critical judgment and becoming complacent. Organizations that intend for their AI systems to be decision-support tools (and thus outside the scope of Article 22) must proactively design their processes and training programs to counter this bias. This includes training staff to maintain a healthy skepticism of the AI's output and empowering them to challenge and override its recommendations without fear of reprisal.
3.3 The "Right to an Explanation"
A key safeguard associated with Article 22 is the right to transparency. While often colloquially referred to as a "right to an explanation," the GDPR's text is more specific. Articles 13, 14, and 15 require controllers to provide data subjects with "meaningful information about the logic involved, as well as the significance and the envisaged consequences" of the automated processing.
This is not a right to be given the model's source code or a complete technical breakdown of a complex algorithm. Rather, it is a right to a comprehensible, non-technical explanation of the main factors that were considered in the decision, the data sources used, and the general logic that led to the outcome. The goal is to demystify the process enough for the individual to understand the basis of the decision and to be able to meaningfully exercise their right to contest it.
The challenge of providing such explanations for "black box" AI models is significant. This is where the field of Explainable AI (XAI) becomes a critical enabler of GDPR compliance. XAI encompasses a range of techniques designed to make the decisions of AI models more interpretable. Methods such as LIME (Local Interpretable Model-agnostic Explanations), which explains individual predictions by approximating the complex model with a simpler one locally, and SHAP (Shapley Additive Explanations), which assigns an importance value to each feature for a particular prediction, can generate the human-readable insights needed to fulfill transparency obligations. By integrating XAI tools into their systems, organizations can generate the "meaningful information" required by the GDPR, thereby enabling both data subjects to understand decisions and human reviewers to conduct meaningful oversight.
3.4 Safeguarding Rights in Practice
When an organization lawfully carries out solely automated decision-making by relying on one of the exceptions in Article 22(2) (contract, law, or explicit consent), it is not absolved of responsibility. On the contrary, Article 22(3) imposes a mandatory obligation to "implement suitable measures to safeguard the data subject's rights and freedoms and legitimate interests."
At a minimum, these safeguards must include the right for the individual to :
Obtain human intervention on the part of the controller.
Express his or her point of view.
Contest the decision.
To operationalize these rights, organizations must establish clear, simple, and easily accessible processes for individuals. For example, a webpage that delivers an automated loan rejection should not lead to a dead end; it must provide a straightforward mechanism—such as a button or a clear contact link—for the user to immediately request a human review of their application. These processes must be properly resourced with trained staff who have the authority and capability to conduct a genuine re-evaluation of the decision.
The Regulatory Horizon: Interplay Between the GDPR and the EU AI Act
The regulatory landscape for AI in Europe is being fundamentally reshaped by the introduction of the EU AI Act. This landmark legislation does not replace the GDPR but rather works in concert with it, creating a dual framework of obligations for organizations developing and deploying AI systems. Navigating this new environment requires a strategic, integrated approach to compliance that recognizes the distinct scopes, overlapping principles, and divergent requirements of these two powerful regulations.
4.1 Scope and Objectives
The GDPR and the EU AI Act are built on different foundations and have different primary objectives.
GDPR: The GDPR is a horizontal regulation focused on the fundamental right to the protection of personal data. Its rules are triggered whenever information relating to an identified or identifiable natural person is processed, irrespective of the technology being used. Its primary goal is to empower individuals and protect their privacy.
EU AI Act: The AI Act is a product safety and fundamental rights framework that regulates AI systems themselves. It adopts a risk-based approach, with the most stringent rules applied to systems that pose the highest risk to health, safety, and fundamental rights. Crucially, the AI Act applies to AI systems regardless of whether they process personal data or non-personal data. Its primary goal is to ensure that AI systems placed on the EU market are safe and trustworthy.
The AI Act explicitly clarifies that it is without prejudice to the GDPR; where an AI system processes personal data, the GDPR applies in its entirety. This means many organizations will have to comply with both sets of rules simultaneously.
4.2 Overlapping Principles and Divergent Obligations
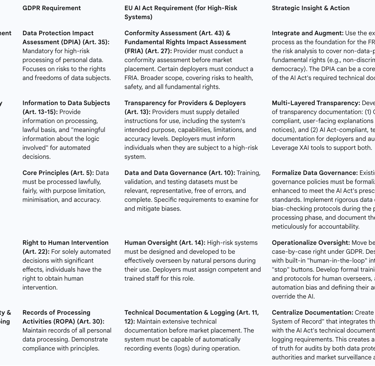
The AI Act was clearly drafted with the GDPR as a model, and as a result, there is significant overlap in their underlying principles. Concepts such as accountability, fairness, transparency, and the need for human oversight are central to both legal frameworks. The requirement in the AI Act for certain deployers of high-risk systems to conduct a Fundamental Rights Impact Assessment (FRIA) is directly analogous to the GDPR's DPIA.
Despite this shared DNA, the AI Act introduces a new layer of highly prescriptive and technical obligations that are distinct from the GDPR's more principle-based approach. The AI Act's risk-based framework categorizes AI systems into four tiers: prohibited, high-risk, limited-risk, and minimal-risk. For systems classified as "high-risk" (e.g., those used in recruitment, critical infrastructure, or law enforcement), the Act imposes a detailed set of ex-ante (before market placement) requirements, including :
Rigorous Data Governance: Mandating that training and testing data be relevant, representative, and checked for biases.
Extensive Technical Documentation: Requiring detailed documentation on the system's construction and performance.
Automatic Logging: Ensuring the system can keep logs of its operations to ensure traceability.
High Levels of Accuracy, Robustness, and Cybersecurity: Meeting specific technical standards.
Conformity Assessments: Undergoing a formal assessment to demonstrate compliance before the system can be sold or used in the EU.
These obligations are more akin to product safety regulations than the data protection principles of the GDPR.
4.3 Strategic Compliance: An Integrated Governance Approach
Treating GDPR and AI Act compliance as separate, siloed workstreams is inefficient, duplicative, and creates a high risk of compliance gaps. The most effective and sustainable strategy is to develop a single, unified AI Governance Framework that integrates the requirements of both regulations into the entire AI lifecycle.
Organizations with mature and well-documented GDPR compliance programs are at a distinct advantage. The processes, documentation, and governance structures already in place for the GDPR can be leveraged and extended to form the backbone of an AI Act compliance strategy. For example:
The existing DPIA process can be augmented to become the FRIA by expanding the scope of the risk assessment to cover all fundamental rights, not just data protection.
The Record of Processing Activities (ROPA) maintained under GDPR Article 30 can provide much of the foundational information needed for the AI Act's technical documentation requirements.
Existing data governance policies developed for GDPR compliance can be enhanced to meet the more prescriptive standards of the AI Act regarding data quality and bias mitigation.
The following table provides a comparative analysis of the key obligations under both regulations for a high-risk AI system, offering a practical tool for identifying compliance gaps and developing an integrated strategy.