Designing AI Systems for GDPR Compliance: A Comprehensive Guide
🎯 Designing AI Systems for GDPR Compliance 🛡️: Master how to create AI systems that meet GDPR requirements and understand the ripple effects 🌊 these rules have on data protection 🗂️, privacy 🤫, and AI innovation 💡.
Staff


This report provides a definitive guide for organizations seeking to achieve compliance with the General Data Protection Regulation (GDPR) throughout the entire lifecycle of their Artificial Intelligence (AI) systems. The central challenge addressed is the inherent tension between the data-intensive nature of AI innovation and the GDPR's foundational principles of personal data protection. This analysis demonstrates that GDPR compliance, rather than being a barrier, serves as a critical framework for building trustworthy, ethical, and sustainable AI. Achieving this requires a proactive, risk-based approach anchored in the legal mandate of Data Protection by Design and by Default. As the regulatory landscape converges with the introduction of the EU AI Act, and guidance from bodies like the UK's Information Commissioner's Office (ICO) and the European Data Protection Board (EDPB) continues to evolve, a holistic and integrated compliance strategy is not merely advisable but essential for lawful and successful AI deployment.
Foundational Legal and Ethical Framework
This section establishes the core legal and ethical principles that underpin the entire compliance journey. It moves beyond simple definitions to analyze how these principles are challenged and reshaped by the unique characteristics of AI.
The GDPR-AI Nexus: Core Principles Reimagined
1.1 Lawfulness, Fairness, and Transparency: Establishing a Valid Legal Basis
The cornerstone of GDPR compliance for any AI system is Article 5(1)(a), which mandates that all processing of personal data must be lawful, fair, and transparent. These three principles are not independent pillars but a deeply interconnected triad that forms the foundation of any compliant AI project.
Lawful Basis (Article 6) Before any personal data is processed—whether for training, testing, or deployment—a valid lawful basis under Article 6 must be identified and documented. For AI applications, the most relevant, and often most complex, bases are 'Consent' and 'Legitimate Interests'.
Consent: To be valid, consent must be freely given, specific, informed, and unambiguous, signified by a clear affirmative act. This presents a significant challenge for AI development, where the purposes for data processing can be broad or evolve over time. For instance, if an organization wishes to collect a wide range of data to explore various predictive models, the ICO suggests that consent may be the most appropriate lawful basis, provided individuals are clearly informed about these exploratory activities.
Legitimate Interests: This is a frequently invoked basis for AI model training, but it is not a default option. It requires a rigorous three-part test: identifying a legitimate interest, demonstrating that the processing is necessary to achieve it, and balancing this interest against the rights, freedoms, and interests of the data subject. The EDPB has set a high bar for this assessment, demanding a case-by-case analysis. The ICO has noted that activities like large-scale web scraping to gather training data pose particular risks to the balancing test, as individuals are often unaware their data is being used, which severely impacts their ability to exercise their rights.
Fairness and Transparency The principle of fairness extends beyond non-discrimination. It requires that personal data be processed only in ways that individuals would reasonably expect and not in any manner that could have unjustified adverse effects on them. This applies to both the process of the AI system and its ultimate outcome.
Transparency is the vehicle for achieving fairness. It obligates organizations to be clear, open, and honest with individuals from the outset about how and why their data is being processed. In the context of AI, this includes informing users about the logic behind AI-driven decisions and providing comprehensive privacy notices before their data is used to train a model.
The relationship between these three principles is causal and reinforcing. A failure in transparency directly undermines fairness because processing data in a way an individual is not aware of inherently violates their reasonable expectations. This finding of unfairness can, in turn, invalidate the lawful basis for processing. For example, if a 'legitimate interest' is claimed but the processing has an unfairly detrimental impact on individuals, the balancing test would fail, rendering the processing unlawful. This demonstrates that a technically valid legal basis is insufficient on its own; it must be supported by transparent practices and fair outcomes to be truly compliant.
1.2 Purpose Limitation & Data Minimisation: The Core Tension with AI
Two of the GDPR's core principles, purpose limitation and data minimisation, are in direct tension with the common practices of AI development, which often thrive on vast datasets and exploratory analysis.
Purpose Limitation (Article 5(1)(b)) This principle mandates that personal data be collected for "specified, explicit, and legitimate purposes" and not be further processed in a manner incompatible with those initial purposes. This is a challenge for AI systems, particularly general-purpose models or those developed through exploratory data analysis where the final application is not known at the outset.
To navigate this, organizations should clearly distinguish between different phases of the AI lifecycle, each with its own defined purpose and lawful basis. For example, the purpose of "research and development" is distinct from the purpose of "deployment for live credit scoring". Furthermore, the GDPR offers some flexibility, as it presumes that further processing for scientific or statistical purposes is not incompatible with the original purpose, provided appropriate safeguards are in place.
Data Minimisation (Article 5(1)(c)) This principle requires that personal data processed must be "adequate, relevant and limited to what is necessary" for the specified purpose. This appears to conflict with the "data hungry" nature of many machine learning models, which often improve in performance with more data.
However, this tension is often based on a misinterpretation of the principle. Data minimisation is not a strict cap on data volume but a principle of necessity and efficiency. It does not prohibit the use of large datasets, but it does prohibit the use of unjustifiably large or irrelevant datasets. The legal requirement forces developers to rigorously justify every feature and data point in relation to the model's specific purpose and required level of statistical accuracy. If a model can achieve a sufficient and justifiable level of performance with less data, then using more is a violation of the principle. This reframes a legal hurdle as a best practice for robust and efficient model engineering, shifting the focus from "how much data can we acquire?" to "what is the minimum data we need to achieve our justified purpose?". Technical solutions such as pseudonymization, which reduces the 'personality' of data, and the use of synthetic or federated data, are crucial for meeting this obligation.
1.3 Accuracy, Storage Limitation, and Integrity
Rounding out the core data protection principles are three further obligations critical to AI governance.
Accuracy (Article 5(1)(d)): Personal data must be accurate. For AI, this is paramount, as inaccurate training data inevitably leads to inaccurate models that can produce biased, discriminatory, and unfair outcomes. This principle applies not only to the input data but also to the inferences and predictions the AI system generates about individuals.
Storage Limitation (Article 5(1)(e)): Data must be kept in an identifiable form for no longer than is necessary. Organizations must establish and enforce clear data retention policies for all datasets used in the AI lifecycle. Once a model is trained and validated, the training data may no longer be necessary and should be securely deleted, archived, or fully anonymized.
Integrity and Confidentiality (Article 5(1)(f)): Personal data must be processed with appropriate security. AI systems introduce novel security vulnerabilities, such as adversarial attacks, model inversion attacks that can infer training data, and data leakage through model outputs. A robust security posture, including measures like encryption and access controls, must be maintained throughout the AI lifecycle to protect against these threats.
Defining and Operationalizing Fairness in AI
2.1 Interpreting 'Fairness' Under GDPR: Beyond Algorithmic Metrics
The concept of "fairness" is central to both ethical AI development and GDPR compliance. However, the term holds different meanings in the legal and computer science domains.
Under the GDPR, fairness is a broad, context-dependent principle. It means processing personal data in ways that people would reasonably expect, avoiding unjustified adverse effects, and not being unduly detrimental or misleading. It encompasses non-discrimination but is also concerned with the overall balance of interests and power dynamics between the organization and the individual.
This legal definition of fairness is distinct from "algorithmic fairness," a term used by computer scientists to refer to a set of statistical metrics that measure the distribution of a model's outcomes or errors across different demographic groups. Examples include demographic parity (ensuring the rate of positive outcomes is the same for all groups) and equalized odds (ensuring error rates are the same across groups). While these metrics are valuable tools for detecting certain types of bias, they do not capture the full scope of fairness under data protection law, which also considers the context of deployment and the entire processing lifecycle.
2.2 Identifying and Mitigating Bias Across the AI Lifecycle
Unfairness in AI systems often manifests as bias, which can lead to discriminatory outcomes. Bias can be introduced at any stage of the AI lifecycle.
Sources of Bias:
Data Bias: This is the most common source. It includes sampling bias, where the training data is not representative of the real-world population, and historical bias, where the data accurately reflects past societal prejudices, which the model then learns and perpetuates. Amazon's discontinued AI hiring tool, which learned to penalize female candidates based on historical hiring data, is a prominent example of this risk.
Model and Algorithmic Bias: Choices made during development, such as the features selected for the model or the objective it is optimized for, can introduce or amplify bias.
Human and Deployment Bias: The way a system is used in practice can also lead to unfairness. A key example is "automation bias," where human reviewers place excessive trust in an AI's output and fail to critically evaluate its recommendations.
Detection and Mitigation: A multi-faceted approach is required to address bias.
Detection: This involves rigorous data analysis to identify imbalances, the use of statistical fairness metrics to compare outcomes across groups, and the application of Explainable AI (XAI) techniques like LIME and SHAP to understand which data features are driving a model's decisions.
Mitigation: Strategies for mitigation fall into three categories:
Pre-processing: Modifying the training data before model training to correct for imbalances, for example, by reweighing samples or generating synthetic data for underrepresented groups.
In-processing: Adjusting the model's learning algorithm during training to incorporate fairness constraints directly into its optimization process.
Post-processing: Modifying the model's predictions after they have been made, for instance, by applying different decision thresholds for different demographic groups to equalize outcomes.
Organizations must navigate a complex set of trade-offs when implementing these strategies. Efforts to enhance fairness, for instance, may require the processing of sensitive data to test for bias, which increases privacy risks. Similarly, techniques to improve privacy, such as differential privacy, can sometimes reduce a model's overall accuracy. This "Fairness-Accuracy-Privacy" trilemma is not a purely technical problem to be solved by data scientists. It represents a fundamental governance challenge that requires a formal, documented process where legal, ethical, and business leaders collaboratively define the organization's risk appetite and justify the chosen balance.
2.3 Processing Special Category Data for Bias Detection (Article 9)
A significant dilemma arises when trying to ensure non-discrimination. To effectively detect and mitigate bias against groups defined by protected characteristics such as race, ethnic origin, or health status, it is often necessary to process this very data. However, Article 9(1) of the GDPR generally prohibits the processing of such "special categories of personal data."
This prohibition is not absolute. Processing is permitted if one of the conditions in Article 9(2) is met. For bias mitigation, the most relevant condition is typically "substantial public interest," which must be established in Union or Member State law. The EU AI Act, in Article 10(5), provides a specific legal gateway for processing special category data for the purpose of bias monitoring and correction in high-risk AI systems. However, this must be interpreted strictly in line with GDPR requirements, ensuring the processing is strictly necessary and accompanied by robust safeguards, including enhanced security and data minimisation techniques.
Navigating High-Stakes AI Applications
This part focuses on the specific, high-stakes scenarios directly addressed by the GDPR, where the potential for harm to individuals is greatest and the legal requirements are most stringent.
Automated Decision-Making Under Article 22
Article 22 of the GDPR is one of the few provisions that directly regulates the outcomes of algorithmic processing. It establishes specific rights and restrictions for a narrow but highly impactful category of AI applications.
3.1 Defining the Scope: 'Solely Automated' and 'Legal or Similarly Significant Effects'
The core of Article 22 is the right of a data subject "not to be subject to a decision based solely on automated processing, including profiling, which produces legal effects concerning him or her or similarly significantly affects him or her". Understanding the two key phrases in this provision is critical to determining its applicability.
'Solely Automated': A decision is not "solely" automated if there is meaningful human intervention. The ICO provides crucial clarification on this point: for human review to be considered meaningful, it must be more than a token gesture. The review must be carried out by someone who has the authority, competence, and capacity to change the decision and must consider all relevant data. A simple "rubber-stamping" of an AI's recommendation does not constitute meaningful human involvement.
'Legal or Similarly Significant Effects': A "legal effect" is one that impacts an individual's legal rights, such as their entitlement to social benefits or the termination of a contract. A "similarly significant effect" is a broader concept that includes decisions having a serious impact on an individual's circumstances, choices, or opportunities. Examples provided in regulatory guidance include the automatic refusal of an online credit application, e-recruiting practices that filter candidates without human review, and dynamic pricing models that may effectively exclude certain individuals from accessing goods or services.
3.2 Permissible Grounds for Solely Automated Decisions
The general prohibition on solely automated decisions is not absolute. Such processing is permitted under three specific conditions :
It is necessary for entering into, or performance of, a contract between the individual and the organization.
It is authorized by Union or Member State law, which must also include suitable safeguards for the individual's rights.
It is based on the individual's explicit consent.
When such decisions involve special categories of personal data, the conditions are even stricter, typically requiring either explicit consent or a basis in law for reasons of substantial public interest.
3.3 Implementing Mandatory Safeguards
When an organization conducts solely automated decision-making based on the grounds of contractual necessity or explicit consent, it is legally obligated under Article 22(3) to implement suitable measures to safeguard the data subject's rights, freedoms, and legitimate interests. At a minimum, these safeguards must include the right for the individual to :
Obtain human intervention on the part of the controller.
Express his or her point of view.
Contest the decision.
These safeguards are fundamental mechanisms for providing redress and ensuring fairness, allowing individuals to challenge and seek review of decisions that could have a profound impact on their lives.
The Challenge of the 'Black Box': Transparency and the Right to Explanation
One of the most significant challenges AI poses to data protection law is the "black box" problem, where the internal workings of complex machine learning models are opaque even to their creators. This opacity directly conflicts with the GDPR's emphasis on transparency and an individual's ability to understand decisions made about them.
4.1 Deconstructing the 'Right to Explanation'
The GDPR does not contain an explicit, standalone "right to explanation." Rather, this concept is derived from the interplay of several provisions. The transparency requirements of Articles 13, 14, and 15 mandate that individuals be provided with "meaningful information about the logic involved, as well as the significance and the envisaged consequences" of automated decision-making. This is reinforced by the safeguards in Article 22(3), which grant the right to contest a decision, a right that is difficult to exercise without some form of explanation.
The scope and technical feasibility of this right have been the subject of extensive legal and academic debate. The core challenge is that for many sophisticated models, such as deep neural networks, it may be technically impossible to provide a complete, step-by-step rationale for a specific output. However, the legal objective is not necessarily to disclose the full source code or algorithmic architecture. Instead, the goal is to provide an explanation that is sufficient to enable the data subject to understand the primary drivers of the decision and to effectively exercise their right to contest it.
4.2 Leveraging Explainable AI (XAI) for Compliance
Explainable AI (XAI) is a field of artificial intelligence focused on developing methods and techniques that make the results and outputs of AI systems understandable to humans. XAI provides the technical tools necessary to bridge the gap between complex AI models and the GDPR's transparency requirements.
Key XAI frameworks and techniques include:
LIME (Local Interpretable Model-agnostic Explanations): This technique explains an individual prediction by creating a simpler, interpretable model (like a linear model) that approximates the behavior of the complex "black box" model in the local vicinity of that specific prediction.
SHAP (Shapley Additive Explanations): Based on principles from cooperative game theory, SHAP assigns an importance value to each feature for a particular prediction, indicating how much that feature contributed to pushing the model's output from a baseline value to its final prediction.
In practice, if an AI system denies a loan, an XAI tool like SHAP could generate an explanation stating that the decision was primarily influenced by a high debt-to-income ratio and a short credit history. This provides the "meaningful information" required by the GDPR, empowering the individual to understand and potentially contest the decision.
4.3 Balancing Transparency with Other Interests
The push for transparency is not without its own set of competing interests. Full disclosure of a model's logic could expose valuable intellectual property (trade secrets) or create vulnerabilities that could be exploited by malicious actors to "game" or manipulate the system.
To manage this balance, organizations can employ several strategies:
Counterfactual Explanations: This powerful XAI technique provides an explanation by describing the smallest change to an individual's input data that would have altered the decision. For example, "Your loan application would have been approved if your annual income was €5,000 higher." This provides actionable insight to the individual without revealing the inner workings of the model.
Tiered Explanations: Explanations can be tailored to different audiences. An end-user might receive a simple, high-level counterfactual explanation, while a regulator or internal auditor could be granted access to more detailed technical documentation and model scorecards.
A Practical Framework for Compliance by Design
This part translates the legal principles into an operational framework, guiding organizations through the practical steps of embedding data protection into the AI lifecycle.
Data Protection by Design and by Default (Article 25) as the Cornerstone of AI Governance
Article 25 of the GDPR is the lynchpin of a proactive and preventative approach to data protection. It elevates "privacy by design" from a best practice to a legal mandate, requiring organizations to integrate data protection measures into their processing activities from the very beginning and throughout the entire lifecycle.
5.1 A Lifecycle Approach to Data Protection
The core tenet of Article 25 is that data protection cannot be an afterthought; it must be "baked in". For AI systems, this necessitates a structured approach that considers data protection at every stage of development and deployment. A comprehensive AI lifecycle framework for this purpose includes the following phases: Planning, Design, Development, and Deployment, followed by continuous Monitoring and eventual Decommissioning. This approach is fundamentally preventative, designed to identify and mitigate privacy risks before they can cause harm, which is especially critical given the complexity and potential for large-scale impact of AI technologies.
5.2 Practical Implementation Across the AI Lifecycle
Planning/Conception Phase: This initial stage sets the foundation for compliance. It involves clearly defining a specific, explicit, and legitimate purpose for the AI system, establishing a valid lawful basis for the intended data processing, and conducting a preliminary risk screening to determine if a full Data Protection Impact Assessment (DPIA) is required. Fairness considerations must be integrated from the outset, including defining the problem the AI is intended to solve and the scope of its decision-making power.
Data Collection & Preparation Phase: Adherence to the data minimisation principle is paramount. Organizations must carefully determine the minimum categories and volume of data necessary to achieve the defined purpose. This is the stage to implement techniques like anonymization or pseudonymization, or to consider the use of synthetic data to reduce reliance on personal data. Data sources must be vetted for quality, relevance, and potential for inherent bias.
Model Development & Training Phase: Security must be embedded to protect both the training data and the model itself from threats. Bias mitigation techniques should be applied, and model architectures should be chosen with interpretability and the ability to facilitate data subject rights in mind. This is also the phase where advanced Privacy-Enhancing Technologies (PETs) can be integrated into the training process.
Validation & Testing Phase: Before deployment, models must undergo rigorous testing not only for performance but also for data protection vulnerabilities. This includes testing for potential data leakage, re-identification risks, and susceptibility to adversarial attacks. Crucially, performance evaluation should be disaggregated across different demographic groups to identify and address any performance disparities that could lead to discriminatory outcomes.
Deployment & Monitoring Phase: Once live, the system requires ongoing oversight. This includes implementing robust access controls and encryption for data in use. Users must be provided with clear, layered privacy notices and effective controls over their data. Continuous monitoring is essential to detect model drift (degradation in performance over time), emergent biases, and new security threats.
The obligations of Article 25 have a profound effect on the entire AI ecosystem. The responsibility for "data protection by design" extends beyond the organization deploying the AI (the data controller). Under Article 28, controllers must only use data processors (such as AI-as-a-Service vendors) that provide "sufficient guarantees" of compliance. This legal requirement effectively pushes accountability upstream to the developers and producers of AI tools. A controller cannot procure a "black box" AI service and absolve itself of responsibility; it has a due diligence obligation to select vendors whose products are designed to facilitate compliance with data subject rights, transparency, and security. This dynamic creates powerful market pressure for AI vendors to build privacy and compliance features into their products, transforming Article 25 from a mere compliance duty into a market-shaping force that drives innovation in trustworthy AI.
The Data Protection Impact Assessment (DPIA) for High-Risk AI Systems
The Data Protection Impact Assessment (DPIA) is a formal process mandated by Article 35 of the GDPR. It is a critical tool for identifying, assessing, and mitigating data protection risks associated with high-risk processing activities, and it serves as a key mechanism for demonstrating accountability.
6.1 Triggering the DPIA Requirement (Article 35)
A DPIA is mandatory whenever processing is "likely to result in a high risk to the rights and freedoms of natural persons". For AI systems, this threshold is almost invariably met. The ICO has stated emphatically that in the "vast majority of cases," the use of AI will require a DPIA. This is because AI processing frequently involves one or more of the high-risk indicators identified by regulators, including:
The use of new or innovative technologies.
Systematic and extensive evaluation of personal aspects based on automated processing (e.g., profiling) that leads to significant decisions.
Large-scale processing of special categories of data.
The European Data Protection Board (EDPB) advises that if a processing activity meets two or more of its established high-risk criteria, a DPIA is generally required.
6.2 A Step-by-Step Guide to Conducting an AI DPIA
A DPIA is a structured process that should be integrated into the project lifecycle from the earliest possible stage. The following table provides a practical example of the core components of a DPIA for a high-risk AI recruitment tool.


The DPIA process must also include consultation with the Data Protection Officer (DPO) and, where appropriate, with the data subjects themselves. The final report must document the entire process, the risks identified, the mitigation measures chosen, and the DPO's advice. The DPIA is a "living document" that must be regularly reviewed and updated as the AI system and its associated risks evolve.
6.3 Prior Consultation with Supervisory Authorities
A critical final step in the DPIA process arises if, after implementing mitigation measures, the assessment still indicates a high residual risk to individuals' rights and freedoms. In such cases, Article 36 of the GDPR mandates that the organization must consult with the relevant supervisory authority (e.g., the ICO in the UK) before commencing the processing.
Upholding Data Subject Rights in Complex AI Systems
The GDPR grants individuals a suite of rights to control their personal data. Implementing these rights within the complex architecture of AI systems presents significant technical and operational challenges.
7.1 Operationalizing Access, Rectification, and Portability
Right of Access (Article 15): Individuals have the right to obtain confirmation that their data is being processed and to access that data. For AI systems, this includes not only the raw data provided but also information about the logic involved in any automated decisions. Systems must be designed with functionalities to retrieve and provide this information in a clear and intelligible format.
Right to Rectification (Article 16): If personal data is inaccurate, individuals have the right to have it corrected. When this data has been used to train an AI model, complying with a rectification request may necessitate retraining or fine-tuning the model with the corrected data to ensure its future outputs are not based on flawed information.
Right to Data Portability (Article 20): This right allows individuals to receive their personal data in a structured, commonly used, and machine-readable format and to transmit that data to another controller. In an AI context, this applies to data that the individual has "provided," which can include not only data they actively submitted but also observed data such as their usage habits or demographic information used for model training.
7.2 The Right to Erasure ('Right to be Forgotten') in Trained Models (Article 17)
The right to erasure, or the "right to be forgotten," is perhaps the most technically challenging data subject right to implement for AI systems. Article 17 grants individuals the right to have their personal data deleted under certain conditions, such as when the data is no longer necessary for its original purpose or when consent is withdrawn.
The challenge lies in the fundamental nature of machine learning. When data is used to train a model, its informational content is not stored in a discrete, deletable record. Instead, its influence is encoded and distributed across the millions or billions of parameters (weights) that constitute the model's "knowledge". Excising the influence of a single individual's data from a trained model is akin to trying to remove a single egg from a baked cake; it is technically complex, economically prohibitive, and often practically impossible without starting over.
Despite this technical impasse, organizations are not absolved of their legal obligations. Practical strategies and emerging solutions include:
Removal from Datasets: The ICO's guidance clarifies that organizations are expected to be able to remove an individual's data from the training datasets that will be used for future model updates or retraining.
Machine Unlearning: This is an active area of academic research focused on developing algorithms that can cause a model to "forget" specific data points without the need for a complete, costly retraining. However, these techniques are still nascent and not yet proven to be scalable or effective for large, production-grade models.
Modular Design: Building AI systems with a modular architecture may allow for the targeted retraining of only the specific components that were influenced by the data subject's information, reducing the computational burden of an erasure request.
Advanced Technologies and the Future of Compliance
This final part looks to the technological frontier and the evolving regulatory landscape, providing a forward-looking perspective on achieving and maintaining compliance.
Leveraging Privacy-Enhancing Technologies (PETs) for Robust Compliance
Privacy-Enhancing Technologies (PETs) are a class of technologies that embed fundamental data protection principles directly into technical systems. For AI, they offer powerful tools to mitigate privacy risks by design and demonstrate a commitment to robust compliance.
The following table provides a practical overview of three leading PETs, outlining their function, ideal use cases, and key implementation challenges.
8.1 Decentralized Approaches: Federated Learning
Federated learning is a decentralized machine learning technique where a shared global model is trained across numerous devices or servers, each holding its own local data. Instead of pooling raw data in a central location, which creates a single point of failure and high privacy risk, only anonymized or aggregated model updates (such as parameter gradients) are sent to a central server for aggregation. This approach inherently supports the principles of data minimisation and security by design by keeping sensitive data localized. However, it is not a panacea; challenges include high communication costs, dealing with non-identically distributed data across clients, and the fact that model updates themselves can potentially leak information, often requiring the use of other PETs in conjunction.
8.2 Statistical Anonymity: Differential Privacy
Differential privacy is a rigorous mathematical framework that enables the analysis of datasets while providing formal guarantees about the privacy of individuals within that data. It works by injecting carefully calibrated statistical noise into the data or the outputs of an algorithm. This ensures that the results of any analysis will be approximately the same whether or not any single individual's data was included in the dataset, thus protecting against re-identification attacks. In machine learning, a common implementation is Differentially Private Stochastic Gradient Descent (DP-SGD), which clips the influence of any single data point and adds noise during the model training process. The primary challenge is the "privacy-utility trade-off": stronger privacy guarantees require more noise, which can degrade the model's accuracy.
8.3 Computation on Encrypted Data: Homomorphic Encryption
Homomorphic encryption is a groundbreaking cryptographic technique that allows for mathematical computations to be performed directly on encrypted data. This means a third party, such as a cloud provider, could train an AI model or perform inference on sensitive data without ever having access to the decrypted, plaintext information. This offers the highest level of security and confidentiality, making it ideal for use cases in sectors like healthcare and finance where data cannot be exposed. While powerful, its widespread adoption is currently hindered by significant computational overhead, which can make processing times prohibitively slow and expensive, and a high degree of implementation complexity.
The Converging Regulatory Horizon: GDPR and the EU AI Act
The regulatory landscape for AI in Europe is defined by two landmark pieces of legislation: the GDPR and the new EU AI Act. While they have distinct focuses, they are designed to be complementary and, for many AI systems, will apply concurrently.
9.1 Mapping the Overlap: A "Hand-in-Glove" Relationship
The GDPR is a horizontal, technology-neutral law focused on the fundamental right to the protection of personal data. The EU AI Act, in contrast, is a product safety framework that takes a risk-based approach to regulating AI systems themselves, imposing obligations based on the level of risk they pose to health, safety, and fundamental rights.
These two regulations are intended to work "hand-in-glove". Any AI system that processes personal data must comply with the requirements of
both laws. The GDPR provides the foundational data protection rules, while the AI Act adds a layer of AI-specific obligations, particularly for systems classified as high-risk. Where the AI Act does not specify particular data governance rules, the GDPR's provisions apply. The following table provides a comparative analysis of their key data governance obligations.
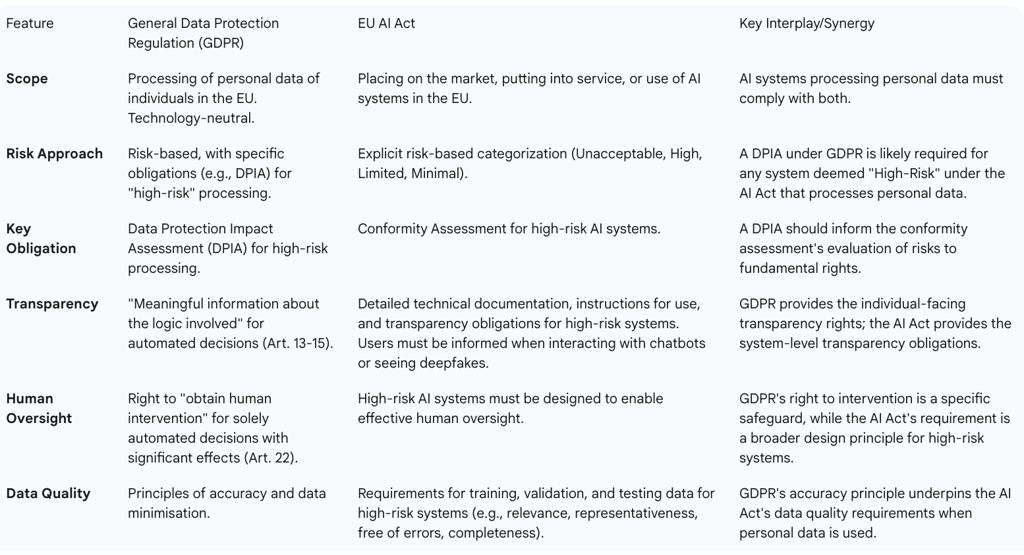
9.2 Leveraging GDPR Compliance for AI Act Readiness
Organizations that have already invested in robust GDPR compliance programs are well-positioned to meet many of the requirements of the AI Act. The processes and principles are highly synergistic.
Risk Assessments: The GDPR's DPIA process provides a strong foundation for the conformity assessments required for high-risk AI systems under the AI Act. The analysis of risks to fundamental rights conducted for a DPIA is directly relevant to the AI Act's requirements.
Human Oversight: The safeguards and processes developed to facilitate the right to human intervention under GDPR's Article 22 align directly with the AI Act's mandate for effective human oversight in high-risk systems.
Transparency and Data Quality: The principles of transparency, accuracy, and data minimisation embedded in the GDPR are echoed and expanded upon in the AI Act's requirements for technical documentation and data governance for high-risk systems.
9.3 Concluding Recommendations: A Unified Strategy for Ethical and Lawful AI
Navigating the complex and converging regulatory landscape for AI requires a unified and holistic governance strategy. Organizations should not treat GDPR and AI Act compliance as separate, siloed activities. Instead, they should build an integrated framework that addresses the shared principles of risk management, transparency, fairness, and accountability.
The proactive, risk-based approach mandated by the GDPR, centered on Data Protection by Design and by Default, is the most effective strategy. Tools like DPIAs and fairness audits should be embraced not as bureaucratic hurdles, but as strategic instruments for building robust, ethical, and trustworthy AI systems. The regulatory environment is dynamic, and continuous monitoring of guidance from the EDPB and national supervisory authorities like the ICO is essential for maintaining compliance.
Ultimately, the GDPR should not be viewed as an impediment to innovation. Instead, it provides the foundational framework for building the kind of trustworthy and human-centric AI that will be essential for gaining long-term social acceptance and achieving sustainable market success.